
Полная версия:
Введение в машинное обучение
При решении задач классификации наиболее эффективным считается бустинг над деревьями решений. Одной из самых популярных библиотек, реализующих бустинг над деревьями решений, является XGBoost (Extreme Gradient Boosting). Загрузка библиотеки и создание классификатора выполняются командами:
import xgboost
clf = xgboost.XGBClassifier(nthread=1)
Применим XGBClassifier для решения задачи Fashion-MNIST:
clf = xgboost.XGBClassifier(nthread=4,scale_pos_weight=1)
clf.fit(X_train, y_train)
nthread – количество потоков, которое рекомендуется устанавливать не по количеству процессорных ядер вычислительной системы.
Результат, который получен в этом случае:
Accuracy of XGBClassifier on training set: 0.88
Accuracy of XGBClassifier on test set: 0.86
Важной особенностью является нечувствительность к нормировке данных. То есть если мы будем рассматривать исходные данные изображения в их первозданном виде, исключив операторы:
##X_train1=X_train1/255.0
##X_test1=X_test1/255.0
Мы получим те же самые показатели качества, что и для нормированных данных.
Примечание. При проведении экспериментов с большим набором данных нужно учесть, что алгоритм довольно долго обучается. В частности, при решении задачи Fashion-MNIST время обучения превышает 10 минут. Программу, решающую задачу Fashion-MNIST с помощью XGBoost (MLF_XGBoost_Fashion_MNIST_001), можно загрузить по ссылке https://www.dropbox.com/s/frb01qt3slqkl6q/MLF_XGBoost_Fashion_MNIST_001.html?dl=0
2.13. Снижение размерности данных. Метод главных компонент
Метод главных компонент (Principal Component Analysis – PCA) – один из «классических» способов уменьшения размерности данных, причем таким образом, чтобы минимизировать потери информации. С его помощью можно выяснить, какие из свойств объектов наиболее влиятельны в процессе принятия классификации. Однако он вполне успешно применяется для сжатия данных и обработки изображений. В машинном обучении метод часто применяется как один из способов понижения размерности до двух или трех с целью отображения объектов классификации или регрессии в виде, понятном для человека, или для ускорения обучения путем «отбрасывания» тех свойств данных, которые менее существенны, то есть вносят меньший вклад в распределение данных. Метод восходит к работам Пирсона и Сильвестра [[65], [66]].
Суть метода заключается в том, что ведется поиск ортогональных проекций с наибольшим рассеянием (дисперсией), которые и называются главными компонентами. Другими словами, ведется поиск ортогональных проекций с наибольшими среднеквадратическими расстояниями между объектами. Для дальнейшего изложения нам потребуются два нестрогих определения.
Определение 1. В теории вероятностей и математической статистике мера линейной зависимости двух случайных величин называется ковариацией. Ковариационная матрица, определяющая такую зависимость, рассчитывается следующим образом:
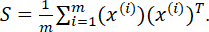
Иначе, учитывая, что X – матрица параметров размерностью m x n (m – количество случайных величин, n – количество параметров или измерений, их определяющих), мы можем записать:
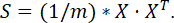
Определение 2. Ненулевой вектор, который при умножении на некоторую квадратную матрицу превращается в самого же себя с числовым коэффициентом, называется собственным вектором матрицы. Другими словами, если задана квадратная матрица S, то ненулевой вектор v называется собственным вектором матрицы, если существует число w – такое, что:
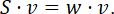
Число w называют собственным значением или собственным числом матрицы S. Алгоритм расчета главных компонент включает два этапа:
Рассчитывается ковариационная матрица S, которая по определению является квадратной матрицей размера n x n, где n – число свойств.
Рассчитывается матрица собственных векторов V размерностью n x n, состоящая из n собственных векторов матрицы, каждый из которых состоит из n компонентов.
Фактически мы получаем n ортогональных измерений, в которых распределены величины x(i).
Из образовавшихся n главных компонент выбирают первые k, которые обеспечивают минимальные потери данных, так, что теряются минимальные отклонения в данных (variation). Вообще говоря, это означает, что данные можно восстановить с ошибкой не меньшей, чем указанные потери.
Другими словами, можно сократить матрицу V, уменьшив тем самым число ортогональных проекций вектора x. Обозначим сокращенную матрицу Vreduced. Затем можно умножить сокращенную матрицу на транспонированную матрицу X:
Z= Vreduced*X.T.
Так мы получим новую матрицу Z, содержащую проекции X на сокращенный набор измерений. Тем самым часть измерений будет потеряна, размерность новой матрицы Z будет меньше X, однако при этом можно отбрасывать малозначимые проекции, вдоль которых значения x(i) меняются незначительно.
Рассмотрим простой пример преобразования двумерного набора данных в одномерный. На рисунке 2.15a слева показан синтетический набор данных, где каждая из 200 точек является объектом в пространстве двух признаков. Набор получен командой:
X = np.dot(np.random.random(size=(2, 2)), np.random.normal(size=(2, 200))).T
Рассчитаем ковариационную матрицу, собственное число и матрицу собственных векторов командами:
S=(1/X.shape[1])*np.dot(X.T,X) #covariance matrix
w, v = np.linalg.eigh(S)
Используя первый или второй вектор матрицы v, мы можем получить два набора взаимно ортогональных значений – z и zz:
vreduced=v[:,1]
vreduced1=v[:,0]
z=np.dot(vreduced,X.T)
zz=np.dot(vreduced1,X.T)
Видно, что дисперсия распределения объектов вдоль горизонтальной оси значительно больше, чем вдоль вертикальной (рисунок 2.15b). Фактически объекты, расположенные на горизонтальной и вертикальной осях, и являются одномерным представлением исходного набора. Видно, что, исключая вертикальную ось (рисунок 2.15b) полностью (вторая главная компонента), мы теряем относительно небольшое количество информации.
Заметим, что объекты можно вновь неточно восстановить в пространстве двух признаков, выполнив обратное преобразование:
Xa= Vreduced*Z.
Однако информацию, относящуюся ко второй главной компоненте, мы, конечно, потеряем (рисунок 2.15с).
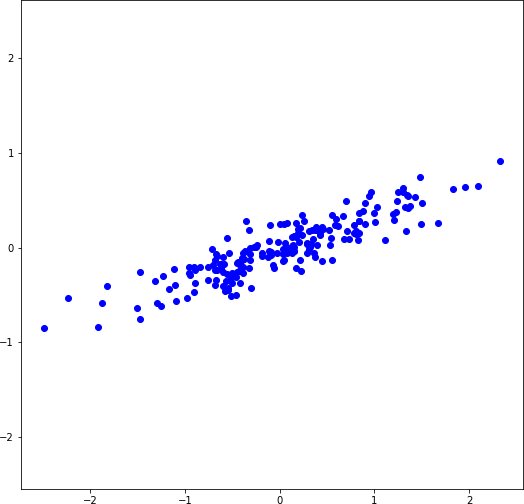
a) Исходный набор данных, где каждый объект имеет два свойства
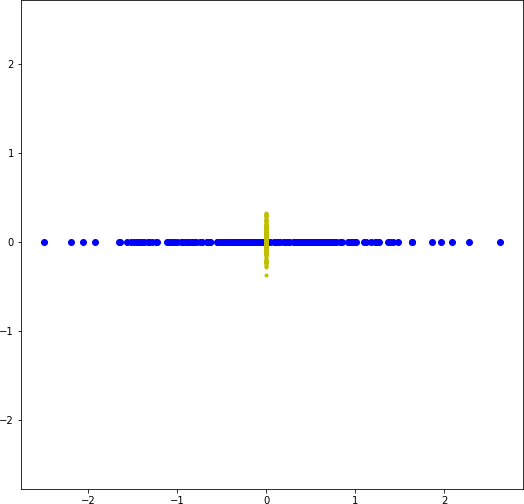
b) Отображение объектов на взаимно перпендикулярные оси (первую и вторую главную компоненты)
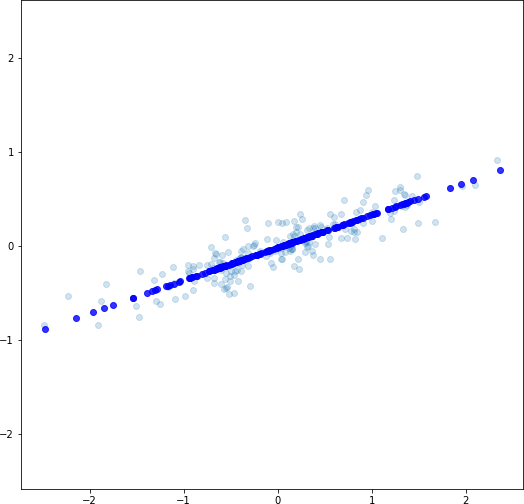
с) Восстановление объектов в двумерном пространстве признаков. Исходное распределение объектов показано полупрозрачными точками
Рисунок 2.15. Преобразование данных при применении PCA
На первый взгляд (рисунок 2.15с) может показаться, что задача PCA является задачей линейной регрессии, однако это не совсем так. Отличие в том, что в задаче линейной регрессии среднеквадратическое расстояние определяется вдоль оси y (оси меток), а в PCA – перпендикулярно главной компоненте (рисунок 2.16).
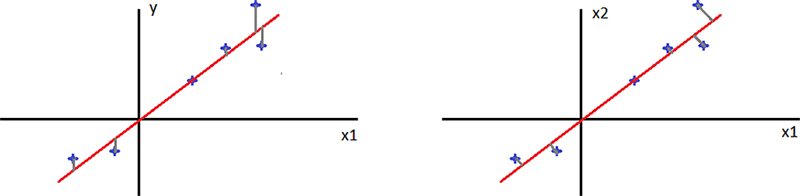
Рисунок 2.16. Представление задач линейной регрессии (слева) и PCA (справа)
Примечание. Полный текст программы расчета главных компонент приведен в MLF_PCA_numpy_001.ipynb – https://www.dropbox.com/s/65y1z7svf7epx1q/MLF_PCA_numpy_001.html?dl=0
Библиотека scikit-learn имеет в своем составе модуль PCA, с помощью которого можно вычислить главные компоненты и найти количество главных компонент, необходимых для обеспечения заданной вариативности новых параметров z.
Примечание. Закрепить навыки работы с PCA в составе библиотеки scikit-learn можно, выполнив задания лабораторной работы ML_lab08_Principal Component Analysis – https://www.dropbox.com/sh/xnjiztxoxpqwos3/AADoUPfNeMnEXapbqb3JHHvla?dl=0
2.14. Контрольные вопросы
Какие параметры регулируют работу алгоритма k-NN и позволяют улучшить качество классификации?
Что такое ядро в алгоритме опорных векторов?
Приведите выражение функции стоимости алгоритма опорных векторов.
Как обучается алгоритм Naïve Bayes?
Укажите достоинства алгоритма Naïve Bayes.
Укажите недостатки алгоритма Naïve Bayes.
Что дает сглаживание по Лапласу в алгоритме Naïve Bayes?
Чем помогает применение логарифмов в алгоритме Naïve Bayes?
Что такое бустинг?
В чем заключается преимущество бустинга над деревьями решений?
Что такое PCA?
Каково минимальное количество главных компонент, получаемых с помощью PCA?
3. Оценка качества методов ML
Для решения конкретной задачи с помощью ML необходимо выбрать соответствующий метод, который дает наилучший результат.
Примечание. Под методом машинного обучения мы понимаем в данном случае реализацию алгоритма или некоторой модели вычислений, которая решает задачу классификации, регрессии или кластеризации.
Для выбора такого метода требуются некоторые показатели, позволяющие оценить методы ML и сравнить их между собой.
Примечание. Программу, которая реализует большую часть примеров данного раздела, можно получить по ссылке – https://www.dropbox.com/s/nc1qx6tjw11t5gs/MLF_Evaluation001.ipynb?dl=0
При этом, как правило, на начальном этапе отбираются методы, удовлетворяющие ограничениям по вычислительной мощности, объему и характеристикам данных, которые есть в распоряжении специалиста по обработке данных. Например, методы глубокого обучения, решающие сложные задачи машинного обучения с высокой точностью, можно использовать, если в распоряжении исследователя имеются большие по объему данные и значительные вычислительные мощности. С другой стороны, если количество примеров меньше числа свойств, то затруднено применение машин опорных векторов (SVM), поскольку они подвержены в таком случае переобучению. Таким образом, отобрав некоторое множество методов для решения задачи и изменяя их параметры (например, коэффициент регуляризации, число слоев нейронных сетей и т.п.), необходимо оценивать результаты их работы, используя один или несколько показателей.
Примечание. Рекомендуется выбрать одну, возможно, интегральную метрику для оценки качества.
К числу таких показателей можно отнести метрики качества, кривые оценки качества, способность к обучению и скорость обучения и решения задачи.
В общем случае метрики оценки качества зависят от предметной области и цели, поставленной перед системой ML, и могут задаваться исследователем. Например, для поисковых машин, выполняющих поиск информации в интернете, это может быть удовлетворенность пользователей (user satisfaction) в результатах поиска, для систем электронной коммерции – доход (amount of revenue), для медицинских систем – выживаемость пациентов (patient survival rates) и т.п. Однако есть некоторый базовый набор метрик, которые применяются достаточно часто при оценке качества алгоритмов классификации, регрессии и кластеризации.
Назначение метрик качества – дать оценку, показывающую, насколько классификация или предсказание, выполненное с применением методов ML, отличается от таковой, выполненной экспертами или другим алгоритмом. При этом часто применяют простейшую метрику – процент (доля) правильно классифицированных примеров. Для оценки ошибок первого и второго рода применяют также еще несколько важных показателей: «точность» (precision), «полноту» (recall), и обобщающие показатели – меры F1 и F (F1 score и F-score).
Примечание. Напомним, что ошибкой первого рода называется ошибка, состоящая в опровержении верной гипотезы, а ошибкой второго рода называется ошибка, состоящая в принятии ложной гипотезы.
Их применение особенно важно в случае неравных по объему классов, когда количество объектов одного типа значительно превосходит количество объектов другого типа. Часто упоминаемый перечень метрик оценки классификаторов, следующий:
Accuracy
Precision
Recall
F1 score
F-score
Area Under the Curve (AUC)
Кроме этого, на практике часто применяются специальные кривые:
1. Precision-Recall curve
2. ROC curve
Кроме метрик оценки качества важным показателем применяемого метода ML является его способность обучаться, то есть улучшать свои показатели точности при увеличении числа примеров. Может оказаться, что метод, который показывает очень хорошие результаты на тренировочном множестве примеров, дает неудовлетворительный результат на тестовом множестве, то есть не обладает нужной степенью обобщения. Баланс между способностью обобщения и точностью может быть найден с помощью «кривых обучаемости», которые в общем случае могут показать, способен ли тот или иной метод улучшать свой результат так, чтобы показатели качества как на тренировочном, так и на тестовом множестве были примерно равны и удовлетворяли требованиям предметной области исследования.
Третий показатель, который становится особенно важным в задачах с большим объемом данных, – скорость обучения и классификации. Методы ускорения работы алгоритмов ML в задачах с большими данными рассматриваются в разделе «Машинное обучение в задачах с большим объемом данных».
3.1. Метрики оценки качества классификации
В настоящее время в задачах машинного обучения для оценки качества классификации наиболее часто используется доля правильных ответов (accuracy) или Correct Classification Rate (ССR) – относительное количество корректно классифицированных объектов (процент или доля правильно классифицированных объектов):
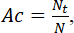
где Nt – количество корректно классифицированных объектов; N – общее число объектов.
Этот показатель является весьма важным, однако если количество объектов в классах существенно неравное (так называемые неравномерные, или «перекошенные», классы – skewed classes), то может случиться так, что очень плохой классификатор будет давать большое значение Aс. Например, если объектов 1-го типа 90% от всего числа объектов, а объектов 2-го типа только 10%, то классификатору достаточно отвечать всегда, что он распознал объект 1-го типа, и доля правильных ответов достигнет 90%. Таким образом, даже если алгоритм никогда правильно не распознает объект 2-го класса, он все равно будет иметь высокий показатель Aс. При этом, если распознавание объектов 2-го класса исключительно важно, показатель Aс будет попросту вводить в заблуждение. Для того чтобы избежать подобной неадекватной оценки, рассматривается еще несколько важных показателей: «точность» (precision), «полнота» (recall), и обобщающий показатель – F1 score (гармоническое среднее или мера F1), которые рассчитываются с помощью следующих выражений:
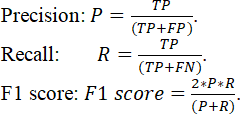
Поясним приведенные выражения.
Рассмотрим случай классификации двух классов (или одного класса номер 1 (positive) и всех остальных классов, которым присвоим номер 0 (negative)). В этом случае возможны следующие ситуации:

Случаи True positive (TP) и True negative (TN) являются случаями правильной работы классификатора, т.е. предсказанный класс совпал с реальностью. Cоответственно, False negative (FN) и False positive (FP) – случаи неправильной работы. FN или ошибка первого рода возникает тогда, когда объект классификации ошибочно отнесен к негативному классу, являясь на самом деле позитивным. Эту ошибку можно рассматривать как признак излишне пессимистического (осторожного) классификатора, т.е. ML-модель предсказала отрицательный результат, когда он является на самом деле положительным. FP или ошибка второго рода, наоборот, признак излишне оптимистического, или неосторожного, классификатора, то есть ML-модель предсказала положительный результат, когда он является на самом деле отрицательным.
Precision (P) будет показывать часть правильно распознанных объектов заданного класса по отношению к общему числу объектов, принятых классификатором за объекты заданного класса. С другой стороны, Recall (R) будет показывать отношение правильно распознанных объектов к общему числу объектов данного класса.
Оба показателя – и P, и R – отражают «путаницу» классификатора. Однако R показывает, насколько классификатор оптимистичен в своих оценках или как часто он «любит» (высокое значение R) присоединять объекты другого класса (negative) к заданному, в то время как P показывает, насколько классификатор «строг» в своих оценках, насколько часто он «отбрасывает» (высокое значение P) объекты нужного (positive) класса. Разумеется, желательно, чтобы оба этих показателя стремились к 1, однако, как правило, в сложных случаях классификации результаты работы балансируют между значениями P и R, то есть большое значение P характерно при малом значении R, и наоборот. На рисунках 3.1a и 3.1b приведены примеры двух линейных классификаторов с высокими значениями precision и recall, где положительные объекты показаны черными точками, отрицательные – желтыми, а граница между классами – красной прямой.
Конец ознакомительного фрагмента.
Текст предоставлен ООО «Литрес».
Прочитайте эту книгу целиком, купив полную легальную версию на Литрес.
Безопасно оплатить книгу можно банковской картой Visa, MasterCard, Maestro, со счета мобильного телефона, с платежного терминала, в салоне МТС или Связной, через PayPal, WebMoney, Яндекс.Деньги, QIWI Кошелек, бонусными картами или другим удобным Вам способом.
Примечания
1
http://www.gartner.com/newsroom/id/3412017
2
https://rapidminer.com/
3
Octave online. – https://octave-online.net/ (2017-04-01).
4
Octave download. – https://www.gnu.org/software/octave/download.html (2017-04-01).
5
The Artificial Intelligence (AI) White Paper. – https://www.iata.org/contentassets/b90753e0f52e48a58b28c51df023c6fb/ai-white-paper.pdf (2021-02-23).
6
Nguyen G. et al. Machine Learning and Deep Learning frameworks and libraries for large-scale data mining: A survey // Artificial Intelligence Review. – 2019. – Т. 52. – № 1. – С. 77–124.
7
Joseph A. Cruz and David S. Wishart. Applications of Machine Learning in Cancer Prediction and Prognosis // Cancer Informatics. – 2006. – Vol. 2. – P. 59–77.
8
Miotto R. et al. Deep learning for healthcare: Review, opportunities and challenges // Briefings in Bioinformatics. – 2017. – Т. 19. – № 6. – С. 1236–1246.
9
Ballester, Pedro J. and John BO Mitchell. A machine learning approach to predicting protein–ligand binding affinity with applications to molecular docking // Bioinformatics. – 2010. – Vol. 26. – № 9. – P. 1169–1175.
10
Mahdavinejad, Mohammad Saeid, Mohammadreza Rezvan, Mohammadamin Barekatain, Peyman Adibi, Payam Barnaghi, and Amit P. Sheth. Machine learning for Internet of Things data analysis: A survey // Digital Communications and Networks. – 2018. – Vol. 4. – Issue 3. – P. 161–175.
11
Farrar, Charles R. and Keith Worden. Structural health monitoring: A machine learning perspective. – John Wiley & Sons, 2012. – 66 p.
12
Lai J. et al. Prediction of soil deformation in tunnelling using artificial neural networks // Computational Intelligence and Neuroscience. – 2016. – Т. 2016. – С. 33.
13
Liakos, Konstantinos et al. Machine learning in agriculture: A review // Sensors. – 2018. – 18(8). – P. 2674.
14
Friedrich Recknagel. Application of Machine Learning to Ecological Modelling // Ecological Modelling. – 2001. – Vol. 146. – P. 303–310.
15
Татаринов В. Н., Маневич А. И., Лосев И. В. Системный подход к геодинамическому районированию на основе искусственных нейронных сетей // Горные науки и технологии. – 2018. – № 3. – С. 14–25.
16
Clancy, Charles, Joe Hecker, Erich Stuntebeck, and Tim O′Shea. Applications of machine learning to cognitive radio networks // Wireless Communications, IEEE. – 2007. – Vol. 14. – Issue 4. – P. 47–52.
17
Ball, Nicholas M. and Robert J. Brunner. Data mining and machine learning in astronomy // Journal of Modern Physics D. – 2010. – Vol. 19. – № 7. – P. 1049–1106.
18
R. Muhamediyev, E. Amirgaliev, S. Iskakov, Y. Kuchin, E. Muhamedyeva. Integration of Results of Recognition Algorithms at the Uranium Deposits // Journal of ACIII. – 2014. – Vol. 18. – № 3. – P. 347–352.
19
Амиргалиев Е. Н., Искаков С. Х., Кучин Я. В., Мухамедиев Р. И. Методы машинного обучения в задачах распознавания пород на урановых месторождениях // Известия НАН РК. – 2013. – № 3. – С. 82–88.
20
Chen Y., Wu W. Application of one-class support vector machine to quickly identify multivariate anomalies from geochemical exploration data // Geochemistry: Exploration, Environment, Analysis. – 2017. – Т. 17. – № 3. – С. 231–238.
21
Hirschberg J., Manning C. D. Advances in natural language processing // Science. – 2015. – Т. 349. – № 6245. – С. 261–266.
22
Goldberg Y. A primer on neural network models for natural language processing // Journal of Artificial Intelligence Research. – 2016. – Т. 57. – С. 345–420.
23
Под методом машинного обучения мы будем понимать реализацию алгоритма или некоторой модели вычислений, которая решает задачу классификации, регрессии или кластеризации с использованием «обучающихся» алгоритмов.
24
Taiwo Oladipupo Ayodele. Types of Machine Learning Algorithms // New Advances in Machine Learning. – 2010. – P. 19–48.
25
Hamza Awad Hamza Ibrahim et al. Taxonomy of Machine Learning Algorithms to classify realtime Interactive applications // International Journal of Computer Networks and Wireless Communications. – 2012. – Vol. 2. – № 1. – P. 69–73.
26
Muhamedyev R. Machine learning methods: An overview // CMNT. – 2015. – 19(6). – P. 14–29.
27
Goodfellow I. et al. Deep learning. – Cambridge: MIT press, 2016. – Т. 1. – № 2.
28
Nassif A. B. et al. Speech recognition using deep neural networks: A systematic review // IEEE Access. – 2019. – Т. 7. – С. 19143–19165.
29
Hastie T., Tibshirani R., Friedman J. Unsupervised learning. – New York: Springer, 2009. – P. 485–585.
30
Kotsiantis, Sotiris B., I. Zaharakis, and P. Pintelas. Supervised machine learning: A review of classification techniques // Emerging Artificial Intelligence Applications in Computer Engineering. – IOS Press, 2007. – P. 3–24.
31
Jain A. K., Murty M. N., Flynn P. J. Data clustering: A review // ACM computing surveys (CSUR). – 1999. – Т. 31. – № 3. – С. 264–323.
32
Wesam Ashour Barbakh, Ying Wu, Colin Fyfe. Review of Clustering Algorithms. Non-Standard Parameter Adaptation for Exploratory Data Analysis // Studies in Computational Intelligence. – 2009. – Vol. 249. – P. 7–28.
33
Mukhamediev R. I. et al. From Classical Machine Learning to Deep Neural Networks: A Simplified Scientometric Review //Applied Sciences. – 2021. – Т. 11. – №. 12. – С. 5541.
34
Мухамедиев Р. И. Методы машинного обучения в задачах геофизических исследований. – Рига, 2016. – 200 с. – ISBN 978-9934-14-876-7.

