
Полная версия:
Жизнь VS Энтропия
Книга Э. Шредингера заканчивается таким пассажем:
«Физикой управляют статистические законы. В биологии мы встречаемся с совершенно иным положением. Единичная группа атомов, существующая только в одном экземпляре, производит закономерные явления, чудесно настроенные одно в отношении другого и в отношении внешней среды, согласно чрезвычайно тонким законам».
«Единичная группа атомов», о которой идет речь, это молекула дезоксирибонуклеииновой кислоты (ДНК). Это открытое в 1869 году вещество к 1944 году было надежно определено как носитель наследуемых свойств живых организмов. Особенно поразительным было осознание того, что эта молекула есть некий код, в котором записана вся информация о живом организме. Более того, это не просто код, а программа развития зародыша организма в полноценную форму. Вот как об этом написано у Шредингера:
«Но термин шифровальный код, конечно, слишком узок. Хромосомные структуры служат в то же время и инструментом, осуществляющим развитие, которое они же предвещают. Они являются и кодексом законов и исполнительной властью или, употребляя другое сравнение, они являются и планом архитектора и силами строителя в одно и то же время».
Помещенный в соответствующую «вычислительную» среду единственный экземпляр ДНК запускает невероятный с точки зрения статистической физики динамический процесс, нарушающий Второе Начало. Для этого достаточно, чтобы в среде поддерживались определенные физические условия (температура, давление, поток света и т. п.) и содержались достаточно простые компоненты.
Книга Э. Шредингера всего на три года опередила новое революционное событие в науке, связанное с понятием энтропии. В 1948 году американский математик К. Шеннон, исследуя передачи сообщений в больших системах связи, пришел к формуле (3) как меры неопределенности состояний таких систем. Это было предопределено аналогией случайного поведения сообщений и микрочастиц. Знакомство Шеннона с корифеем науки XX века Дж. фон Нейманом имело следующие последствия:
«Больше всего меня беспокоило, как это назвать. Я думал назвать это "информацией", но это слово использовалось слишком часто, поэтому я решил назвать это ‘неопределенностью’. Когда я обсуждал это с Джоном фон Нейманом, у него появилась идея получше. Фон Нейман сказал мне: "Вы должны называть это энтропией по двум причинам: во-первых, ваша функция неопределенности использовалась в статистической механике под этим названием, так что у нее уже есть название. Во-вторых, и это более важно, никто не знает, что такое энтропия на самом деле, поэтому в дебатах у вас всегда будет преимущество»».
На идеях К. Шеннона, Р. Хэмминга и других исследователей быстро развилась новая отрасль науки – теория информации. Она базируется на следующих постулатах:
–1) существует множество X элементов, называемых сообщениями;
–2) существует множество A, называемое алфавитом, элементы которого называются символами;
–3) существуют объекты, называемые передатчик, приемник и канал передачи сообщений;
–4) сообщения передаются от передатчика к приемнику по каналу передачи в виде конечных упорядоченных множеств символов;
–5) в силу неустранимой случайности состояний канала передачи, передаваемые сообщения множества X преобразуются им в принятые сообщения множества Y, включающего X;
–6) количество информации1 I(x;y), доставляемое принятым сообщением y при передаче сообщения x, есть
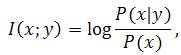
где P(x) – априорное, а P(x|y) – апостериорное распределение вероятностей сообщений x после приема сообщения y. Назовем эти постулаты Системой Символьной Передачи Сообщений (ССПС).
Интегральная характеристика всей системы передачи – это среднее количество взаимной информации I(X;Y) между множествами X и Y. Прямое вычисление по формулам теории вероятности дает
I (X ; Y) = H(X) – H(X | Y),
где H(X), H(X | Y) – априорная и апостериорная энтропия распределений вероятностей множества X, преобразуемого каналом в множество Y [2]. Эта формула определяет глубинный смысл информации, как меры снижения энтропии.
В том же 1948 году математик Н. Винер опубликовал книгу «Кибернетика, или Управление и связь в животном и машине». Эта работа открыла целое направление моделирования «живого» техническими средствами. Дж. фон Нейман формулирует концепцию самовоспроизводящихся машин. В ней он приходит к выводу, что их конструкция требует наличия памяти и канала передачи наследственной информации. Он же формулирует принципы построения вычислительных машин «фон-Неймановского» типа, которые до сих пор доминируют в компьютерном мире. Их особенностью является наличие памяти, хранящейся в ней программы и обрабатывающего ее инструкции процессора. Несколько позже Ф. Розенблатт создает персептрон – альтернативу фон-Неймановским компьютерам. Персептрон непосредственно моделировал процессы распознавания образов в животном мире. Алгоритм работы персептрона задавался не в виде текста на неком языке программирования, а в виде структуры связей между его элементами. Важным его отличием от машин фон-Неймана является наличие процедуры обучения в процессе работы. Сегодня «машины Розенблатта» превратились в нейронные сети, а распознавание образов в искусственный интеллект.
Синтез этих новых направлений привел к формированию обширной области современной науки – информатики. Новое великое открытие XX века – расшифровка в 1953 году Ф. Криком и Дж. Уотсоном структуры молекулы ДНК, стимулировало бурное проникновение ее в генетику. Выяснилось, что эта молекула действительно представляет собой закодированный текст. Алфавитом этого текста служат четыре вида химических соединений – нуклеотидов. Их обозначают буквами А (аденин), Г (гуанин), Т (тимин) и Ц (цитозин). Текст линеен, т. е. представляет собой полимерные цепи, состоящие из названных нуклеотидов. Но его общая структура гораздо сложнее, чем просто последовательность букв (А, Г, Т, Ц). У сложных организмов, состоящих из клеток, имеющих ядро (эукариот), цепи двойные. Буквы одной цепи соединены с буквами другой по принципу комплементарности: аденин соединяется только с тимином, а гуанин только с цитозином. Химические свойства нуклеотидов таковы, что цепи закручиваются в знаменитую «двойную спираль», которую математически корректно было бы называть «двойным винтом». Еще нагляднее модель закручивающейся веревочной лестницы. Аналогия с веревочной лестницей возникает потому, что молекула ДНК способна, сохраняя кручение, сворачиваться в клубок и вообще образовывать сложные вторичные формы. Ее текст может разбиваться на отдельные «главы», называемые хромосомами. Например, ДНК человека образует структуру из 23 отдельных частей, каждая из которых состоит из пары хромосом (рис. 1).
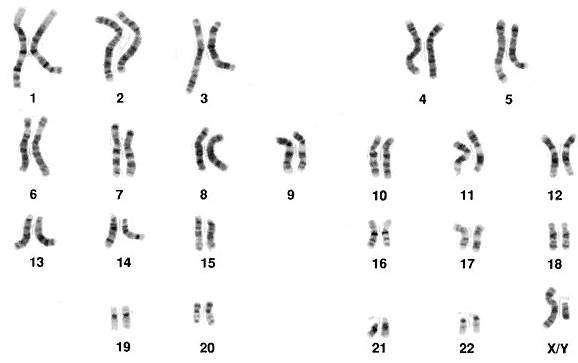
Рис. 1. 23 пары хромосом человека, пара X/Y определяет мужской пол
Хромосомы в парах содержат, как норму, один и тот же «по смыслу» текст. Их поэтому называют гомологичными. Как и положено осмысленному тексту, текст ДНК состоит из «предложений», получивших название генов. При передаче наследственной информации между поколениями живых организмов именно гены являются минимальными неделимыми смысловыми единицами. Заложенный в них смысл – это программа синтеза белков. «Жизнь есть способ существования белковых тел…» – Ф. Энгельс. Уже во времена этого классика было известно, что основным материалом живого служат химические соединения, по-русски названные белки, а по-научному – полипепти́ды. Их формулы представляют собой линейные полимерные цепи, составленные из 20 видов химически модифицированных молекул из класса аминокислот. Иначе говоря, это тоже тексты, но написанные алфавитом из 20 букв. Помимо основных полимерных связей между соседними звеньями цепи, в молекулах белков образуются дополнительные связи между разными их участками. В результате молекулы белков образуют весьма сложные пространственные вторичные, третичные и даже четвертичные структуры. На рис. 2 показана такая структура белка аспартатаминотрансфераза (АСТ), первого белка, текст которого был установлен в полном объеме в 1972 году.
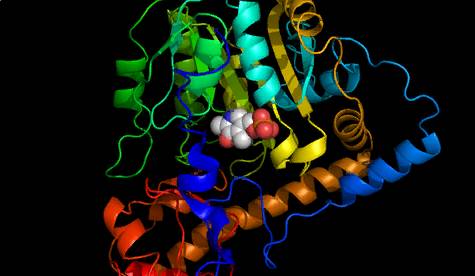
Рис. 2. Молекула белка аспартатаминотрансфераза (АСТ)
Эти свойства белков позволили им образовать следующий по уровню сложности элемент жизни – клетку. Клетка является уже не просто белковой структурой, а процессором, способным выполнять записанные в генетических текстах программы. В клетках высших форм жизни (эукариот) важнейшей операцией является исполнение алгоритма деления (митоз). В процессе исполнения этого алгоритма происходит копирование генетических текстов путем удвоения хромосом и образование пары генетически эквивалентных клеток. Взаимодействие между клетками приводит к их дифференциации и образованию все более сложных структур – органов. Многократное повторение митоза приводит, в конечном счете, к образованию полноценных особей различных видов эукариот. Можно сказать, что человек – это некая n-ричная белковая структура. Компактные образования внутри клетки (органеллы) по-сути являются блоками молекулярного компьютера. Ядро и ядрышко это хранилище самой ДНК («накопитель» генетической памяти). Для достижения клеткой состояния, способного к митозу, она непрерывно производит весь необходимый для поддержания ее статуса живого объекта комплекс белков – рис. 3.
Рис. 3
Каждый ген отвечает за производство определенного белка, в некоторых случаях – нескольких белков. Для разделения текста ДНК на предложения-гены в нем существуют специально закодированные знаки – «генетические точки». Производство белка начинается с процесса, называемого транскрипцией. В транскрипции участвует только одна из ветвей ДНК, которая определяется по наличию определенного маркера-стартера начала текста. Суть этого процесса состоит в отображении предложений языка ДНК на язык другого носителя генетической информации – матричных рибонуклеиновых кислот (мРНК). Также этот носитель называют информационной РНК (иРНК). Термин транскрипция здесь отражает аналогию по переписыванию текста, например, английского, в алфавит звуков речи (фонем). При этом могут выбрасываться (сплайсинг) и трансформироваться куски текста ДНК (сравните английские daughter и [do:te]). Для определения направления чтения текста мРНК на его краях образуются специальные маркеры «начало» и «конец». Оформленный таким образом текст затем транслируется в молекулы одного или нескольких белков. Термином трансляция в информатике принято называть перевод с одного языка на другой. В данном случае производится перевод предложений языка мРНК на язык белков.
Предложения языка мРНК обладают некоторой «грамматикой». Во-первых, имеются химические знаки «начало» и «конец», которые не определяют формулу белка, а лишь управляют процессом трансляции (они получили названия «5’-кэп» и «3’-кэп»). Эту же роль играют примыкающие к ним не транслируемые области (НТО). Собственно формулу белка определяет кодирующая последовательность – рис. 4.

Рис. 4. Грамматика предложений мРНК.
Алфавит и, соответственно, текст кодирующей последовательность мРНК наследуется от ДНК заменой одной буквы (тимин (Т) на урацил (У)). Иначе говоря, это четверка букв-нуклеотидов (А, Г, У, Ц) или в латинском алфавите (A, G, U, C). Алфавит языка белков содержит двадцать букв, химически представляющих собой остатки α-L-аминокислот. Вопрос «как кодирующие последовательности мРНК из четырех нуклеотидов хранят информацию о последовательностях белковых молекул из двадцати аминокислотных остатков» занимал умы многих выдающихся ученых в 50-е годы. Среди них физики Г. Гамов и Р. Фейнман, биохимики Ф. Крик и Дж. Уотсон и многие другие. Были предложены различные виды генетического кода, основанные на чисто информационных подходах. В теории информации к тому времени уже были решены многие задачи оптимального кодирования сообщений. Казалось, что генетический код может иметь отношение к одному из таких решений. Наиболее компактный код при кодировании сообщений относится к классу «кодов без запятой», т. е. в алфавите нет выделенного знака, разделяющего отдельные смысловые единицы («слова»). В современной письменности естественных языков таковыми служат «пробел», «запятая» или другие знаки препинания. Если полагать, что «запятые» проставляются безошибочно, то выделение отдельных слов – тривиальная задача. Но, например, в новгородских берестяных грамотах разделители почти не вписывались в текст, и эта задача становилась иногда весьма трудной, а при определенном контексте, однозначно неразрешимой. Коды без запятой, обладающие свойством однозначного решения такой задачи называются префиксными. Информатиками еще в начале 60-ых годов XX-го века найдены оптимальные (имеющие статистически минимальную длину сообщений) способы построения кодов без запятой (код Фано, код Хаффмена). Одна из гипотез относительно генетического кода, выдвинутая Ф. Криком, базировалась именно на этих идеях. В коде без запятой слова имеют разную длину, но любая их комбинация, даже записанная подряд без разделителей, может быть декодирована, т. е. разделена на слова, единственным образом. Эта идея казалась весьма продуктивной, а при некоторых предположениях даже объясняла возникновение сакрального числа 20 аминокислот. Но в итоге оказалась неверной.
Простой способ построить однозначно декодируемый код без запятой – сделать все его слова одной длины. Такие коды называются блочными. По этому пути пошел Г. Гамов, предложивший первый вариант генетического кода в 1954 году. Для кодирования 20 букв-аминокислот в четырехбуквенном алфавите минимальная необходимая длина слов равна трем (42<20< 43). Примечательно, что при определенных допущениях код Гамова также давал объяснение загадочному числу 20. Более того, в части идеи трехбуквенного кодирования без запятой он оказался правильным. Однако в прочих деталях эта гипотеза, как и все другие, оказались неверны. Природа перехитрила целую группу выдающихся умов, применив, на первый взгляд, совсем не оптимальное решение. Это выявилось путем прямых физико-химических расшифровок формул аминокислот и белков.
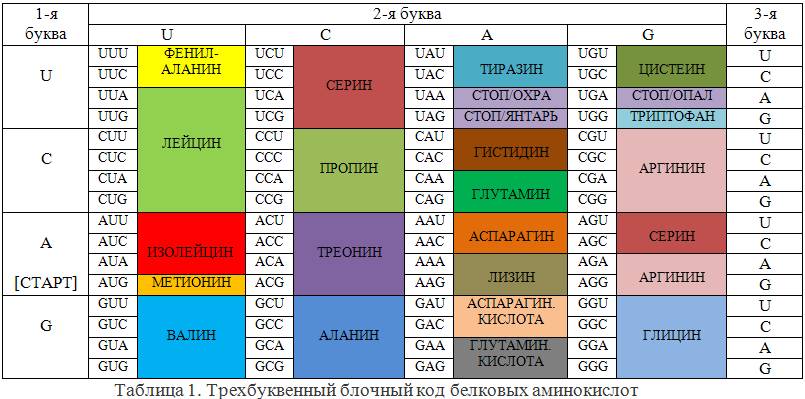
Трехбуквенный блочный код для двадцати аминокислот сильно избыточен: 20<<43=64. Однако избыточность кода, как и избыточность вообще, дает возможность борьбы с ошибками в работе любых систем. В теории информации построение корректирующих кодов, позволяющих путем математических процедур выявлять и автоматически исправлять такие ошибки, является одной из основных задач. Не является ли и здесь избыточность следствием решения природой этой задачи? В таблице 1 приведен реальный генетический код. Трехбуквенные слова кода из алфавита (A, G, U, C) называют кодонами. Из 64 кодонов 61 используется для кодирования 20-ти аминокислот, а три выполняют функции точки в конце генов (стоп-кодоны). Один из кодирующих кодонов, а именно метионин (AUG), выполняет особую роль – все предложения языка белков начинаются с него. Поэтому его еще называют стартовым кодоном, хотя он может появляться и внутри предложений. Код действительно избыточен – почти все аминокислоты имеют несколько вариантов кодирования. Однако легко заметить, что в ряде случаев действует следующее правило: «кодоны одной и той же аминокислоты отличаются только последней буквой».
В этих случаях ошибки в последних буквах кодонов корректируется системой передачи генетической информации на этапе ДНК → белки. Например, любые замены последних букв у кодонов валина, пропина, треонина, аланина и глицина не отражаются на синтезированных клеткой белках. То же можно сказать о четырех из шести кодонах серина и аргинина (стоит отметить, что указанные замены в оставшихся кодонах переводят эти аминокислоты друг в друга). Как физически происходит коррекция ошибок.
Во-первых, в клетках действует защитный механизм, который носит название репарации (от англ. repair – ремонт, починка). Специальные белки, также закодированные в ДНК, способны распознавать нарушения химической структуры отдельных нуклеотидов и либо восстанавливать ее, либо удалять «испорченную букву» с последующей достройкой ее в тексте по принципу комплементарности. Другие специальные белки сшивают разрезанные, например радиацией, цепи ДНК. Двойная цепь ДНК – это код с повторением с точки зрения теории информации. Его избыточность здесь используется для поддержания правильности генетического текста в ядре-накопителе клеточного компьютера. Но ошибки могут возникать и в каналах передачи информации, которые активно используются при построении белков.
Построение молекулы белка начинается с расплетения ветвей ДНК и выделения в одной из них «осмысленного» участка – гена. Это участки между старт- и стоп- кодонами включительно. К «обнаженному» участку ДНК подсоединяются нуклеотиды из алфавита мРНК по принципу комплементарности. После полной транскрипции гена молекула мРНК отделяется от ДНК. К ней для устойчивости подсоединяются «голова» и «хвост» (см. рис. 4) и грамматически законченная молекула выводится из ядра клетки в цитоплазму. Ее голова находит органеллу рибосому (см. рис. 3) и они соединяются в удивительный физико-химический механизм, который можно назвать декодером-транслятором. Молекула мРНК протаскивается через рибосому с шагами в три нуклеотида, т. е. в один кодон. На каждом шаге к выделенному кодону подсоединяется специальная молекула транспортной РНК (тРНК). Молекулы тРНК также вырабатываются на ДНК и выводятся в цитоплазму, состоящую в основном из бульона аминокислот. Каждая тРНК имеет в своем составе антикодон – кодон, комплементарный к выделенному на рибосоме. Каждый вид молекулы тРНК несет антикодон, соответствующий определенному виду аминокислоты и именно этот вид (буква из алфавита аминокислот) прикрепляется к определенному ее концу и транспортируется к рибосоме. При соединении антикодона с кодоном на рибосоме эта буква химически присоединяется к концу синтезируемой цепочки белка. Появление стоп-кодона высвобождает белковую цепь из рибосомы. Далее обычно происходят посттрансляционные химические реакции построенной цепи с другими белками-ферментами до полной готовности молекулы белка к выполнению своей функции в организме. Именно способность нескольких видов тРНК транспортировать одну и ту же аминокислоту исправляет ошибки кодирования в матрицах ДНК и мРНК.
Откуда в клетках берутся нуклеотиды и аминокислоты, т. е. буквы алфавитов генетических текстов? Нуклеотиды синтезируются непосредственно в клетках в процессе обмена веществ. То же относится и ко многим аминокислотам, но у высших животных некоторые из них не синтезируются самим организмом. Те из них, которые необходимы для построения белков, называют незаменимыми. Такие «буквы» должны поступать извне с пищей в готовом виде. Для человека таких аминокислот насчитывают восемь, причем некоторые из них не содержаться в растительном мире. Поэтому чистое вегетарианство в принципе невозможно. Индийские брамины обходят этот принцип, употребляя молочные продукты от священных коров.
Что если третья буква в кодонах возникла вследствие естественного отбора более устойчивой системы передачи информации? Эта мысль не однажды возникала у генетиков. В книге Е.В. Кунина [3] читаем:
«…современный универсальный генетический код гораздо более надежен, чем был бы случайный, по отношению к мутационным и, вероятно также, к трансляционным ошибкам. Эта устойчивость проявляется и в очевидной неслучайности структуры кода, выражающейся в первую очередь в том, что серия кодонов, которые отличаются только третьей позицией, кодирует либо одну и ту же, либо две подобные аминокислоты, и в других особенностях соответствия кодонов аминокислотам (Koonin and Novozhilov, 2009). Примечательно, что предполагаемый предковый «дублетный» код, в котором третья позиция не несла никакой информации, мог быть даже более надежным, чем современный (Novozhilov and Koonin, 2009)».
Почему этот отбор не привел к коду, исправляющему хотя бы все одиночные ошибки? Что это за «предполагаемый предковый «дублетный» код»? Что по этому поводу может сказать информатика?
Для блоковых кодов в теории кодирования существует понятие расстояние Хэмминга [4]. Для пары слов (α, β) расстояние Хэмминга d(α, β) равно числу несовпадений букв в одинаковых позициях. Для того чтобы в блоковом коде была возможность исправить любую одиночную ошибку необходимо и достаточно, чтобы для любой пары слов выполнялось d(α, β)>2. Для двухбуквенного кода это невозможно. Для трехбуквенного кода это влечет вывод: код может состоять только из q слов, где q – объем алфавита. Например, можно взять слова-серии {xxx}. В четырехбуквенном алфавите таких слов всего четыре. Слишком скудной была бы такая жизнь. Она была бы гораздо разнообразней с четырехбуквенными кодонами в том же алфавите, но с исправлением любых однократных ошибок в любом кодоне. Покажем, как можно было бы решить такую задачу.
Еще в середине прошлого века были открыты алгебраические коды над алфавитами, содержащими q = pm букв, где p – простое число. В нашем случае q = 4, p =m =2. Чтобы применить эти достижения информатики в нашем случае, достаточно приписать буквам алфавита (A, G, U, C) способность складываться и умножаться, какая присуща числам. Переобозначим их для удобства так: U≡0, C≡1, A≡a, G≡b (переобозначение может быть и любым другим). Введем таблицы сложения и умножения символов (0, 1, a, b)
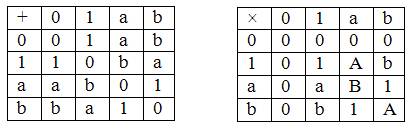
Введением этих таблиц мы определили то, что в математике называется полем Галуа GF(22). Символы 0, 1 обозначают нуль и единицу этого поля. Из таблиц нетрудно увидеть, что они действительно ведут себя почти как обычные нуль и единица (только 1+1=0). Про символы a, b этого уже сказать нельзя. Например, для них
a+a=0, b+b=0, a+b=a – b=1, a2=b=a+1, b2=a=b+1, ab=1.
Несмотря на эти особенности, все основные соотношения алгебры в поле Галуа сохраняются. Можно определить код, как множество векторов x=[x1, x2, x3, x4], удовлетворяющих матричному уравнению
H· x = 0,
где H – матрица
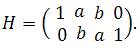
Нетрудно найти, что все определители, составленные из пар столбцов этой матрицы не равны нулю в GF(4). Как доказано в теории алгебраического кодирования [4, с 48], это гарантирует, что для всех пар слов из {x} расстояние Хэмминга d >2. Это означает, что при любой одиночной замене букв в кодоне ошибка может быть исправлена по принципу максимального правдоподобия: «найдется только один правильный кодон, который можно получить одной обратной заменой». Более того, если произойдут две любые замены, то правильного кодона все равно не получится и ошибка будет обнаружена (H· x ≠0,). Правда, однозначно исправить ее по принципу максимального правдоподобия уже невозможно.
Полученный код имеет свойство: «в любых двух фиксированных позициях слова встречаются все возможные пары символов алфавита, которые однозначно определяют символы в другой паре». Это означает, что всего слов 16. В таблице 2 представлен гипотетический генетический код, первые две позиции букв в котором выбраны как в реальном коде таблицы 1 и сохранены те же его компоненты. Вместо третьей буквы кодонов в нем теперь стоит пара букв, обозначенная общим знаком #. Так как теперь слов только 16, а не 64, пяти аминокислотам не достается кодонов (написаны в таблице белым шрифтом).
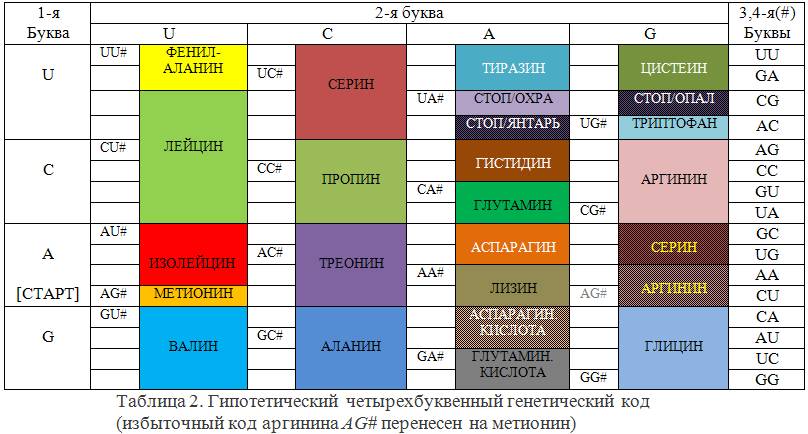
Каков может быть механизм исправления ошибок? В принципе, он аналогичен уже существующему. В ДНК должны быть включены цепи продуцирования тРНК, антикодоны которых для каждого вида аминокислот комплементарны не только основному кодону, но и всем словам, получающимся из него однократными заменами букв. Нетрудно найти, что таких слов в данном коде 12. Они образуют алгебраический шар в поле GF(4) радиусом единица с центром в основном кодоне. Построенный код обладает свойством «все шары радиуса единица с центрами в кодовых словах не пересекаются». Именно это свойство и гарантирует исправление одиночных ошибок по принципу максимального правдоподобия. Реальный генетический код этим свойством не обладает и потому в нем невозможно исправить все такие ошибки. Если отказаться от исправления всех ошибок, то можно и в новом коде закодировать все те же аминокислоты, какие присутствуют в реальном коде и даже расширить этот список.
Описанный выше процесс синтеза белков на рибосоме «буква за буквой» в информатике называется последовательным каналом передачи информации. В таком канале, помимо замен, возможны (и реально происходят), выпадения и вставки букв. Такие ошибки более «опасны», так как они нарушают блоковый характер кода. В теории связи говорят о нарушении синхронизации, в генетике – о сбое «окна» считывания. Что происходит в результате передачи с такими ошибками? Если код не обнаруживает их, а код таблицы 1 именно так устроен, то в синтезированной последовательности наступят серьезные изменения. Весьма вероятно, что возникнет ошибочный стоп-кодон и получится «лишенный смысла» обрубок молекулы белка.

