


Полная версия:
Жизнь 3.0. Быть человеком в эпоху искусственного интеллекта
Мы приблизились к возможному ответу на наш исходный вопрос о том, как грубая физическая материя может породить нечто представляющееся настолько эфемерным, абстрактным и бестелесным, как разум: он кажется нам таким бестелесным из-за своей субстрат-независимости, из-за того, что живет своей жизнью, которая не зависит от физических деталей его устройства и не отражает их. Говоря коротко, вычисление – это определенная фигура пространственно-временного упорядочения атомов, и важны здесь не сами атомы, а именно эта фигура! Материя не важна.
Другими словами, “хард” здесь материя, а фигура – это “софт”. Субстрат-независимость вычисления означает, что AI возможен: разум не требует ни плоти, ни крови, ни атомов углерода.
Благодаря этой субстрат-независимости изобретательные инженеры непрерывно сменяют одну технологию внутри компьютера другой, радикально улучшенной, но не требовавшей замены “софта”. Результат во всех отношениях нагляден в истории запоминающих устройств. Как показывает рис. 2.8, стоимость вычисления сокращается вдвое примерно каждые два года, и этот тренд сохраняется уже более века, снизив стоимость компьютера в миллион миллионов миллионов (в 1018) раз со времен младенчества моей бабушки. Если бы все сейчас стало в миллион миллионов миллионов раз дешевле, то сотой части цента хватило бы, чтобы скупить все товары и услуги, произведенные или оказанные на Земле в тот год. Такое сильное снижение цены отчасти объясняет, почему сейчас вычисления проникают у нас повсюду, переместившись из отдельно стоящих зданий, занятых вычисляющими устройствами, в наши дома, автомобили и карманы – и даже вдруг оказываясь в самых неожиданных местах, например в кроссовках.

Рис. 2.8
С 1900 года вычисления становились вдвое дешевле примерно каждые пару лет. График показывает, какую вычислительную мощность, измеряемую в количестве операций над числами с плавающей запятой в секунду (FLOPS), можно было купить на тысячу долларов{5}. Частные случаи вычислений, которые соответствуют одной операции над числами с плавающей запятой, соответствуют 105 элементарным логическим операциям вроде обращения бита (замены 0 на 1, и наоборот) или одного срабатывания гейта NAND.
Почему развитие наших технологий позволяет им удваивать производительность с такой регулярной периодичностью, обнаруживая то, что математики называют экспоненциальным ростом? Почему это сказывается не только на миниатюризации транзисторов (тренд, известный как закон Мура), но, и даже в большей степени, на развитии вычислений в целом (рис. 2.8), памяти (рис. 2.4), на море других технологий, от секвенирования генома до томографии головного мозга? Рэй Курцвейл называет это явление регулярного удвоения “законом ускоряющегося возврата”.
В известных мне примерах регулярного удвоения в природных явлениях обнаруживается та же самая фундаментальная причина, и в том, что нечто подобное происходит в технике, нет ничего исключительного: и тут следующий шаг создается предыдущим. Например, вам самим приходилось переживать экспоненциальный рост сразу после того, как вас зачали: каждая из ваших клеточек, грубо говоря, ежедневно делится на две, из-за чего их общее количество возрастает день за днем в пропорции 1, 2, 4, 8, 16 и так далее. В соответствии с наиболее распространенной теорией нашего космического происхождения, известной как теория инфляции, наша Вселенная в своем младенчестве росла по тому же экспоненциальному закону, что и вы сами, удваивая свой размер за равные промежутки времени до тех пор, пока из крупинки меньше любого атома не превратилась в пространство, включающее все когда-либо виденные нами галактики. И опять причина этого заключалась в том, что каждый шаг, удваивающий ее размер, служил основанием для совершения следующего. Теперь по тому же закону стала развиваться и технология: как только предыдущая технология становится вдвое мощнее, ее можно использовать для создания новой технологии, которая также окажется вдвое мощнее предыдущей, запуская механизм повторяющихся удвоений в духе закона Мура.
Но с той же регулярностью, как сами удвоения, высказываются опасения, что удвоения подходят к концу. Да, действие закона Мура рано или поздно прекратится: у миниатюризации транзистора есть физический предел. Но некоторые люди думают, что закон Мура синонимичен регулярному удвоению нашей технической мощи вообще. В противоположность им Рэй Курцвейл указывает, что закон Мура – это проявление не первой, а пятой технологической парадигмы, переносящей экспоненциальный рост в сферу вычислительных технологий, как показано на рис. 2.8: как только предыдущая технология перестает совершенствоваться, мы заменяем ее лучшей. Когда мы не можем больше уменьшать вакуумные колбы, мы заменяем их полупроводниковыми транзисторами, а потом и интегральными схемами, где электроны движутся в двух измерениях. Когда и эта технология достигнет своего предела, мы уже представляем, куда двинуться дальше: например, создавать трехмерные интегральные цепи или делать ставку на что-то отличное от электронов.
Никто сейчас не знает, какой новый вычислительный субстрат вырвется в лидеры, но мы знаем, что до пределов, положенных законами природы, нам еще далеко. Мой коллега по MIT Сет Ллойд выяснил, что это за фундаментальный предел, и мы обсудим его в главе 6, и этот предел на целых 33 порядка (то есть в 1033 раза) отстоит от нынешнего положения вещей в том, что касается способности материи производить вычисления. Так что если мы будем и дальше удваивать производительность наших компьютеров каждые два – три года, для достижения этой последней черты нам понадобится больше двух столетий.
Хотя каждый универсальный компьютер способен на те же вычисления, что и любой другой, некоторые из них могут отличаться от прочих своей высокой производительностью. Например, вычисление, требующее миллионов умножений, не требует миллионов различных совершающих умножение модулей с использованием различных транзисторов, как показано на рис. 2.6, – требуется только один такой модуль, который можно использовать многократно при соответствующей организации ввода данных. В соответствии с этим духом максимизации эффективности большинство современных компьютеров действуют согласно парадигме, подразумевающей разделение всякого вычисления на много шагов, в перерывах между которыми информация переводится из вычислительных модулей в модули памяти и обратно. Такая архитектура вычислительных устройств была разработана между 1935 и 1945 годами пионерами компьютерных технологий – такими, как Алан Тьюринг, Конрад Цузе, Преспер Эккерт, Джон Мокли и Джон фон Нейман. Ее важная особенность заключается в том, что в памяти компьютера хранятся не только данные, но и его “софт” (то есть программа, определяющая, что надо делать с данными). На каждом шагу центральный процессор выполняет очередную операцию, определяющую, что именно надо сделать с данными. Еще одна часть памяти занята тем, чтобы определять, каков будет следующий шаг, просто пересчитывая, сколько шагов уже сделано, она так и называется – счетчик команд: это часть памяти, где хранится номер исполняемой команды. Переход к следующей команде просто прибавляет единицу к счетчику. Для того чтобы перейти к нужной команде, надо просто задать программному счетчику нужный номер – так и поступает оператор “если”, устраивая внутри программы петлевой возврат к уже пройденному.
Современным компьютерам удается значительно ускорить выполнение вычислений, проводя их, что называется, “параллельно”, в продолжение идеи повторного использования одних и тех же модулей: если вычисление можно разделить на части и каждую часть выполнять самостоятельно (поскольку результат одной не требуется для выполнения другой), то тогда эти части можно вычислять одновременно в разных составляющих “харда”.
Идеально воплощение параллельности достигается в квантовом компьютере. Пионер теории квантовых вычислений Дэвид Дойч утверждал в полемическом запале, что “квантовый компьютер распределяет доступную ему информацию по бесчисленному множеству копий себя самого во всем мультиверсуме” и решает благодаря этому здесь, в нашей Вселенной, любую задачу гораздо быстрее, потому что, в каком-то смысле, получает помощь от других версий самого себя{6}. Мы пока еще не знаем, будет ли пригодный для коммерческого использования квантовый компьютер создан в ближайшие десятилетия, поскольку это зависит и от того, действительно ли квантовая физика работает так, как мы думаем, и от нашей способности преодолеть связанные с его созданием серьезнейшие технические проблемы, но и коммерческие компании, и правительства многих стран мира вкладывают ежегодно десятки миллионов долларов в реализацию этой возможности. Хотя квантовый компьютер не поможет в разгоне заурядных вычислений, для некоторых специальных типов были созданы изобретательные алгоритмы, способные изменить скорость кардинально – в частности, это касается задач, связанных со взломом криптосистем и обучением нейронных сетей. Квантовый компьютер также способен эффективно симулировать поведение квантово-механических систем, включая атомы, молекулы и новые соединения, заменяя измерения в химических лабораториях примерно в том же ключе, в каком расчеты на обычных компьютерах заменили, сделав ненужными, измерения в аэродинамических трубах.
Что такое обучение?
Хотя даже карманный калькулятор легко обгоняет меня в состязании на быстроту в арифметических подсчетах, он никогда не улучшит своих показателей ни по быстроте вычислений, ни по их точности, сколько бы ни тренировался. Он ничему не учится, и каждый раз, когда я, например, нажимаю кнопку извлечения квадратного корня, он вычисляет одну и ту же функцию, точно повторяя одни и те же действия. Точно так же первая компьютерная программа, обыгравшая меня в шахматы, не могла учиться на своих ошибках и каждый раз просчитывала одну и ту же функцию, которую умный программист разработал, чтобы оценить, насколько хорош тот или иной следующий ход. Напротив, когда Магнус Карлсен в возрасте пяти лет проиграл свою первую игру в шахматы, он начал процесс обучения, и это принесло ему восемнадцать лет спустя титул чемпиона мира по шахматам.
Способность к обучению, как утверждается, – основная черта сильного интеллекта. Мы уже видели, как кажущийся бессмысленным фрагмент неживой материи оказывается способным запоминать и вычислять, но как он может учиться? Мы видели, что поиск ответа на сложный вопрос подразумевает вычисление некоторых функций, и определенным образом организованная материя может вычислить любую вычислимую функцию. Когда мы, люди, впервые создали карманные калькуляторы и шахматные программы, мы как-то организовали материю. И теперь, для того чтобы учиться, этой материи надо как-то, просто следуя законам физики, реорганизовывать себя, становясь все лучше и лучше в вычислении нужных функций.
Чтобы демистифицировать процесс обучения, давайте сначала рассмотрим, как очень простая физическая система может научиться вычислять последовательность цифр в числе π или любом другом числе. Выше мы видели, как холмистую поверхность с множеством ям между холмами (рис. 2.3) можно использовать в качестве запоминающего устройства: например, если координата одной из ям точно равна х = π и поблизости нет никаких других ям, то, положив шарик в точку с координатой х = 3, мы увидим, как наша система вычисляет отсутствующие знаки после запятой, просто наблюдая, как шарик скатывается в ямку. Теперь предположим, что поверхность сделана из мягкой глины, поначалу совершенно плоской как стол. Но если какие-то фанаты-математики будут класть шарики в одни и те же точки с координатами, соответствующими их любимым числам, то благодаря гравитации в этих точках постепенно образуются ямки, и со временем эту глиняную поверхность можно будет использовать, чтобы узнать, какие числа она “запомнила”. Иными словами, глина выучила, как ей вычислить значащие цифры числа π.
Другие физические системы, в том числе и мозг, могут учиться намного эффективнее, но идея остается той же. Джон Хопфилд показал, что его сеть пересекающихся нейронов, о которой шла речь выше, может учиться подобным же образом: если вы раз за разом приводите ее в одни и те же состояния, она постепенно изучит эти состояния и будет возвращаться в какое-то из них, оказавшись где-то поблизости. Вы хорошо помните членов вашей семьи, поскольку часто их видите, и их лица всплывают в вашей памяти всякий раз, как только ее подталкивает к этому что-либо связанное с ними.
Теперь благодаря нейронным сетям трансформировался не только биологический, но и искусственный интеллект, и с недавнего времени они начали доминировать в такой исследовательской области, связанной с искусственным интеллектом, как машинное обучение (изучение алгоритмов, которые улучшаются вследствие приобретения опыта). Прежде чем углубиться в то, как эти сети могут учиться, давайте сначала поймем, как они могут выполнять вычисления. Нейронная сеть – это просто группа нейронов, соприкасающихся друг с другом и потому способных оказывать взаимное влияние. Ваш мозг содержит примерно столько же нейронов, сколько звезд в нашей Галактике – порядка сотен миллиардов. В среднем каждый из этих нейронов контактирует примерно с тысячей других через переходы, называемые синапсами – именно сила этих синаптических связей, которых насчитывается примерно сотни триллионов, кодирует большую часть информации в вашем мозгу.
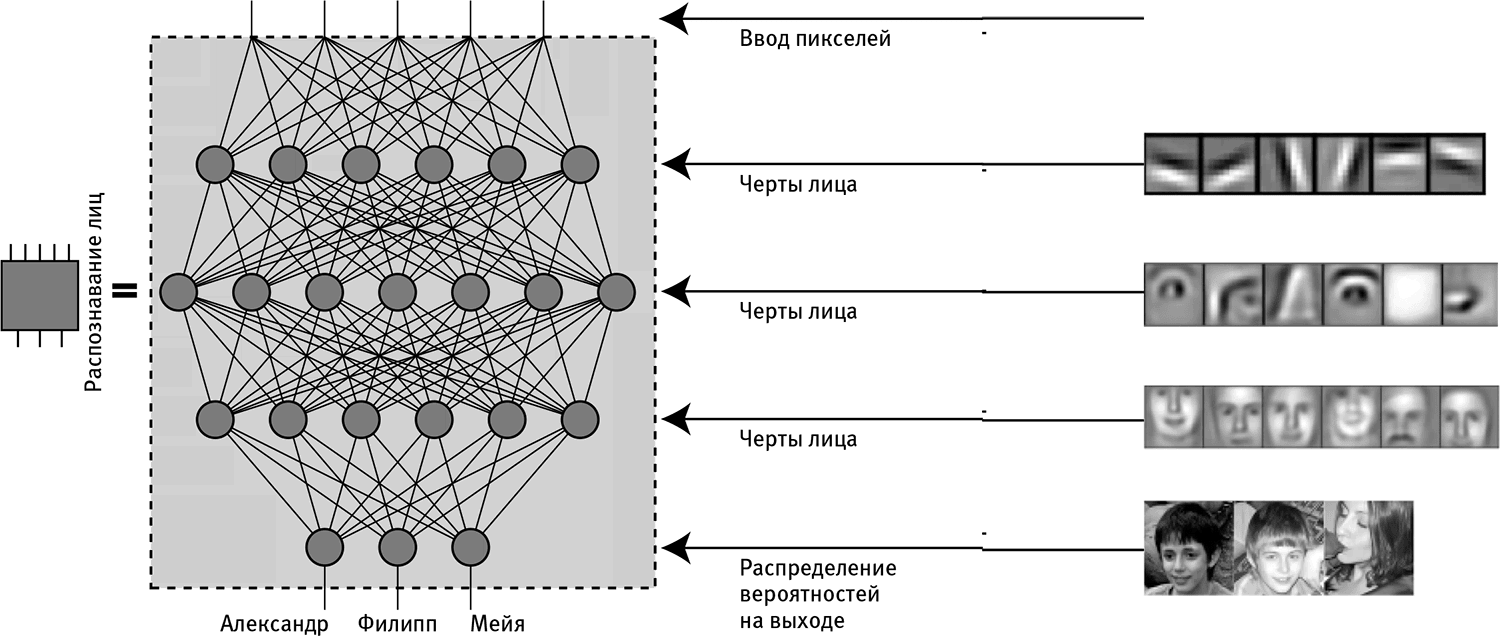
Рис. 2.9
Сеть из нейронов может выполнять вычисления функций так же, как это делает сеть из гейтов NAND. Например, сети искусственных нейронов обучились по вводимым числам, представляющим собой яркость пикселей изображения, давать на выходе числа, соответствующие вероятностям, что на этих изображениях тот или иной человек. Каждый искусственный нейрон (желтый кружок) вычисляет взвешенную сумму чисел, отправленных ему через связи (прямые линии) от нейронов предыдущего слоя, применяет простую функцию и посылает результат нейронам следующего слоя – чем дальше, тем больше вычисляется подробностей. Типичная нейронная сеть, способная распознавать лица, содержит сотни тысяч нейронов. На этом рисунке для простоты показана лишь жалкая горсточка.
Мы можем схематически изобразить нейронную сеть в виде точек, представляющих нейроны, и соединяющих их линий, которые представляют синапсы (см. рис. 2.9). Настоящие синапсы – это довольно сложные электрохимические устройства, совсем не похожие на эту схематическую иллюстрацию: они включают в себя разные части, которые называют аксонами и дендритами; есть много разновидностей нейронов, которые действуют по-разному, и точные детали того, как и когда электрическая активность в одном нейроне влияет на другие нейроны, все еще остаются предметом дальнейших исследований. Однако уже сейчас ясно, что нейронные сети могут достичь производительности человеческого уровня во многих удивительно сложных задачах, даже если на время забыть обо всех этих сложностях и заменить настоящие биологические нейроны чрезвычайно простыми имитирующими их устройствами, совершенно одинаковыми и подчиняющимися очень простым правилам. В настоящее время наиболее популярная модель такой искусственной нейронной сети представляет состояние каждого нейрона одним числом и силу каждого синапса – тоже одним числом. В этой модели при каждом действии каждый нейрон обновляет свое состояние, вычисляя среднее арифметическое от состояния всех присоединенных к нему нейронов с весами, в качестве которых берутся силы их синаптической связи. Иногда еще прибавляется константа, а к результату применяется так называемая функция активации, дающая число, которым будет выступать в качестве состояния данного нейрона на следующем такте[15]. Самый простой способ использовать нейронную сеть как функцию заключается в том, чтобы сделать ее прямой, превратив в канал передачи, где информация направляется лишь в одну сторону, как показано на рис. 2.9, загружая на вход функции верхний слой нейронов и считывая выход со слоя нейронов внизу.
Успешное использование этой простой нейронной сети представляет нам еще один пример независимости от субстрата: нейронная сеть обладает колоссальной вычислительной силой, которая, вне всякого сомнения, не зависит от мелких подробностей в ее устройстве. В 1989 году Джордж Цибенко, Курт Хорник, Максвелл Стинчкомб и Халберт Уайт доказали нечто замечательное: простые нейронные сети вроде только что описанной универсальны в том смысле, что они могут вычислять любую функцию с произвольной точностью, просто приписывая соответствующие значения числам, которыми характеризуются силы синаптических связей. Другими словами, эволюция, вероятно, сделала наши биологические нейроны такими сложными не потому, что это было необходимо, а потому, что это было более эффективно, и потому, что эволюция, в отличие от инженеров-людей, не получает наград за простоту и понятность предлагаемых конструкций.
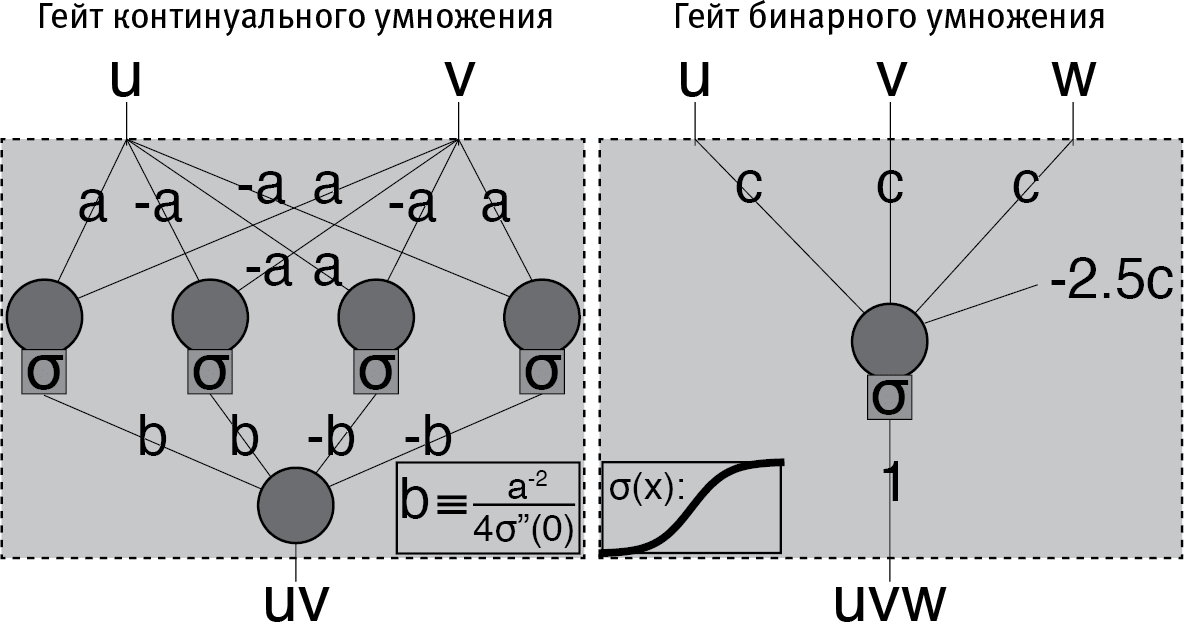
Рис. 2.10
Вещество может производить умножение, используя не гейты NAND, как на рис. 2.7, а нейроны. Для понимания ключевого момента здесь не требуется вникать в детали, достаточно только отдавать себе отчет, что нейроны (как биологические, так и искусственные) не только способны производить математические действия, но их для этого требуется значительно меньше, чем гейтов NAND. Вот еще факультативные детали для упертых фанатов математики: кружочками обозначено сложение, квадратики обозначают применение функции σ, а прямые отрезки – умножение на число, которое этот отрезок пересекает. На входе – вещественное число (слева) или бит (справа). Умножение становится сколь угодно точным при а → 0 (слева) и при с → ∞ (справа). Левая сеть работает при любой функции σ(х), имеющей изгиб в нуле σ”(0) ≠ 0), что можно доказать разложением функции σ(х) по формуле Тейлора. Для сети справа надо, чтобы функция σ(х) стремилась к нулю и к единице при очень малых и очень больших х соответственно, так чтобы соблюдалось условие uvw = 1, только когда u + v + w = 3. (Эти примеры взяты из статьи моего студента Генри Лина: https://arxiv.org/abs/1608.08225, проверена 18 мая 2018.) Комбинируя умножения и сложения, можно вычислять любые полиномы, с помощью которых, как известно, мы можем получить апроксимацию любой гладкой функции.
Впервые услышав об этом, я был озадачен: как что-то до такой степени простое может вычислить нечто произвольно сложное? Например, как вы сможете даже просто-напросто что-то перемножать, когда вам разрешено только вычислять взвешенные средние значения и применять одну фиксированную функцию? Если вам захочется проверить, как это работает, на рис. 2.10 показано, как всего пять нейронов могут перемножать два произвольных числа и как один нейрон может перемножить три бита.
Хотя вы можете доказать теоретическую возможность вычисления чего-либо произвольно большой нейронной сетью, ваше доказательство ничего не говорит о том, можно ли это сделать на практике, располагая сетью разумного размера. На самом деле, чем больше я об этом думал, тем больше меня удивляло, что нейронные сети и в самом деле так хорошо работали.
Предположим, что у вас есть черно-белые мегапиксельные фотографии, и вам их надо разложить в две стопки – например, отделив кошек от собак. Если каждый из миллиона пикселей может принимать одно из, скажем, 256 значений, то общее количество возможных изображений равно 2561000000, и для каждого из них мы хотим вычислить вероятность того, что на нем кошка. Это означает, что произвольная функция, которая устанавливает соответствие между фотографиями и вероятностями, определяется списком из 2561000000 позиций, то есть числом большим, чем атомов в нашей Вселенной (около 1078). Тем не менее нейронные сети всего лишь с тысячами или миллионами параметров каким-то образом справляются с такими классификациями довольно хорошо. Как успешные нейронные сети могут быть “дешевыми” в том смысле, что от них требуется так мало параметров? В конце концов, вы можете доказать, что нейронная сеть, достаточно маленькая для того, чтобы вписаться в нашу Вселенную, потерпит грандиозное фиаско в попытке аппроксимировать почти все функции, преуспев лишь в смехотворно крошечной части всех вычислительных задач, решения которых вы могли бы от нее ждать.
Я получил огромное удовольствие, разбираясь с этой и другими, связанными с ней, загадками вместе со студентом по имени Генри Лин. Среди разнообразных причин испытывать благодарность к своей судьбе – возможность сотрудничать с удивительными студентами, и Генри – один из них. Когда он впервые зашел в мой офис и спросил, хотел бы я поработать с ним, я подумал, что, скорее, мне надо было бы задавать такой вопрос: этот скромный, приветливый юноша с сияющими глазами из крошечного городка Шревепорт в штате Луизиана уже успел опубликовать восемь научных статей, получить премию Forbes 30-Under-30 и записать лекцию на канале TED, получившую более миллиона просмотров – и это всего-то в двадцать лет! Год спустя мы вместе написали статью, в которой пришли к удивительному заключению: вопрос, почему нейронные сети работают так хорошо, не может быть решен только методами математики, потому что значительная часть этого решения относится к физике.
Мы обнаружили, что класс функций, с которыми нас познакомили законы физики и которые, собственно, и заставили нас заинтересоваться вычислениями, – это удивительно узкий класс функций, потому что по причинам, которые мы все еще не полностью понимаем, законы физики удивительно просты. Более того, крошечная часть функций, которую могут вычислить нейронные сети, очень похожа на ту крошечную часть, интересоваться которыми нас заставляет физика! Мы также продолжили предыдущую работу, показывающую, что нейронные сети глубокого обучения (слово “глубокое” здесь подразумевает, что они содержат много слоев) гораздо эффективнее, чем мелкие, для многих из этих функций, представляющих интерес. Например, вместе с еще одним удивительным студентом MIT, Дэвидом Ролником, мы показали, что простая задача перемножения n чисел требует колоссальных 2n нейронов для сети с одним слоем и всего лишь около 4n нейронов в глубокой сети. Это помогает объяснить не только возросший энтузиазм среди исследователей AI по отношению к нейронным сетям, но также и то, зачем эволюции понадобились нейронные сети у нас в мозгу: если мозг, способный предвидеть будущее, дает эволюционное преимущество, в нем должна развиваться вычислительная архитектура, пригодная для решения именно тех вычислительных задач, которые возникают в физическом мире.
Теперь, когда мы знаем, как нейронные сети работают и как вычисляют, давайте вернемся к вопросу о том, как они могут учиться. В частности, как может нейронная сеть улучшать свои вычислительные способности, обновляя состояние своих синапсов.
Канадский психолог Дональд Хебб в своей книге 1949 года The Organization of Behavior, вызвавшей живой отклик, утверждал, что если бы два соседних нейрона часто оказывались активны (“светились”) одновременно, то их синаптическая связь усиливалась бы, обучая их включать друг друга – эта идея нашла отражение в популярной присказке “Связаны вместе, светятся вместе”. Хотя до понимания в подробностях, как именно происходит обучение в настоящем мозгу, нам еще далеко, и исследования показывают, что ответы во многих случаях должны будут далеко выходить за рамки простых предложенных правил вроде того, что стало известно как “обучение по Хеббу”, даже эти простые правила, тем не менее, способны объяснить, каким образом происходит обучение нейронных сетей во многих интересных случаях. Джон Хопфилд ссылался на обучение по Хеббу, которое позволило его исключительно простой искусственной нейронной сети сохранить много сложных воспоминаний путем простого повторения. Такое экспонирование информации в целях обучения обычно называют “тренировкой”, когда речь идет об искусственных нейронных сетях (а также о животных или о людях, которым надо приобрести определенный навык), хотя слова “опыт”, “воспитание” или “образование” тоже подходят. В искусственных нейронных сетях, лежащих в основе современных систем AI, обучение по Хеббу заменено, как правило, более сложными правилами с менее благозвучными названиями, такими как обратное распространение ошибки (backpropagation) или спуск по стохастическому градиенту (stochastic gradient descent), но основная идея одна и та же: существует некоторое простое детерминированное правило, похожее на закон физики, с помощью которого синапсы со временем обновляются. Словно по волшебству, пользуясь этим простым правилом, нейронную сеть можно научить чрезвычайно сложным вычислениям, если задействовать при обучении большие объемы данных. Мы пока еще не знаем точно, какие правила использует при обучении наш мозг, но, каков бы ни был ответ, нет никаких признаков, что эти правила нарушают законы физики.

