
Полная версия:
Библиотеки Python Часть 2. Практическое применение

Джейд Картер
Библиотеки Python Часть 2. Практическое применение
Слово от автора
Дорогие читатели!
Python – это не просто язык программирования, это универсальный инструмент, который помогает нам решать самые разные задачи, от обработки данных до создания искусственного интеллекта. Во второй части книги я постарался показать, как эти инструменты можно применять в реальных проектах, делая вашу работу не только более эффективной, но и увлекательной.
Каждая глава этой части – это шаг в сторону практики, где мы вместе преодолеваем границы теории и углубляемся в реальные примеры и кейсы. Мне важно было продемонстрировать, что с помощью Python можно не только писать код, но и находить решения там, где это казалось невозможным.
Эта книга – результат моего опыта, наблюдений и экспериментов. Я надеюсь, что она станет для вас не просто руководством, а вдохновением, мотивирующим к изучению новых возможностей. Помните, что любое знание становится ценным, когда его можно применить на практике.
Спасибо за то, что выбрали эту книгу. Пусть она станет вашим верным спутником в мире Python и откроет двери к новым достижениям.
С уважением,
Джейд картер
Глава 1. Работа с большими данными
1.1 Распределенная обработка данных с Dask и PySparkРабота с большими объемами данных требует инструментов, которые позволяют эффективно распределять вычисления между несколькими процессорами или даже серверами. Python предлагает две мощные библиотеки для таких задач – Dask и PySpark. Каждая из них разработана для обработки больших данных, но они имеют свои уникальные особенности и подходы. Разберем их по отдельности, чтобы понять, как их использовать, и приведем примеры.
Dask: инструмент для масштабирования локальных задач
Dask – это библиотека, которая позволяет расширить вычисления на вашем компьютере, эффективно распределяя их между ядрами процессора или несколькими машинами в кластере. Она идеально подходит для тех случаев, когда объем данных превышает доступную оперативную память, но вы хотите сохранить гибкость работы с Python.
Основные особенности Dask:
1. Dask совместим с большинством популярных библиотек Python, таких как Pandas, NumPy и Scikit-learn.
2. Он поддерживает ленивые вычисления: операции выполняются только при необходимости.
3. Dask позволяет работать как с массивами данных (аналог NumPy), так и с таблицами (аналог Pandas).
Пример использования Dask для обработки данных:
Предположим, у нас есть большой CSV-файл с данными о продажах. Его объем превышает объем оперативной памяти, поэтому обычные инструменты, такие как Pandas, не могут загрузить файл целиком.
```python
import dask.dataframe as dd
# Загрузка большого CSV-файла с помощью Dask
df = dd.read_csv('sales_data_large.csv')
# Выполнение простых операций (например, фильтрация по значению)
filtered_df = df[df['sales'] > 1000]
# Группировка и вычисление суммарных продаж
sales_summary = filtered_df.groupby('region')['sales'].sum()
# Выполнение вычислений (операции "ленивые", пока мы не вызовем .compute())
result = sales_summary.compute()
# Вывод результатов
print(result)
```
Объяснение кода:
1. `dd.read_csv()`: Вместо загрузки всего файла в память, Dask загружает его частями (по "чанкам").
2. Ленивые вычисления: Все операции, такие как фильтрация и группировка, откладываются до вызова `compute()`.
3. Параллельное выполнение: Dask автоматически распределяет работу между всеми доступными ядрами процессора.
Когда использовать Dask:
– Когда ваши данные не помещаются в память.
– Когда вы уже используете библиотеки Python, такие как Pandas или NumPy, и хотите масштабировать их.
– Когда вам нужно быстро настроить распределенные вычисления на одной или нескольких машинах.
PySpark: инструмент для кластерного вычисления
PySpark – это Python-интерфейс для Apache Spark, платформы, разработанной специально для обработки больших данных. Spark работает на кластерах, что позволяет масштабировать вычисления до сотен машин.
PySpark особенно популярен в случаях, когда данные хранятся в распределенных системах, таких как HDFS или Amazon S3.
Основные особенности PySpark:
1. PySpark работает с данными в формате **RDD** (Resilient Distributed Dataset) или DataFrame.
2. Он поддерживает широкий спектр операций, включая трансформации данных, машинное обучение и потоковую обработку.
3. PySpark интегрируется с Hadoop и другими системами для хранения больших данных.
Пример использования PySpark для обработки данных:
Допустим, у нас есть большие данные о транзакциях, хранящиеся в формате CSV, и мы хотим вычислить среднее значение транзакций по каждому клиенту.
```python
from pyspark.sql import SparkSession
# Создаем сессию Spark
spark = SparkSession.builder.appName("TransactionAnalysis").getOrCreate()
# Читаем данные из CSV-файла
df = spark.read.csv('transactions_large.csv', header=True, inferSchema=True)
# Выполняем трансформации данных
# 1. Фильтрация транзакций с нулевой суммой
filtered_df = df.filter(df['amount'] > 0)
# 2. Группировка по клиенту и вычисление среднего значения
average_transactions = filtered_df.groupBy('customer_id').avg('amount')
# Показ результатов
average_transactions.show()
# Останавливаем Spark-сессию
spark.stop()
```
Объяснение кода:
1. Создание SparkSession: Это точка входа для работы с PySpark.
2. `spark.read.csv()`: Загружаем данные в формате DataFrame, который поддерживает SQL-подобные операции.
3. Трансформации: Операции, такие как фильтрация и группировка, выполняются параллельно на всех узлах кластера.
4. Результат: PySpark возвращает распределенные данные, которые можно сохранить или преобразовать.
Когда использовать PySpark:
– Когда вы работаете с кластерами и хотите обрабатывать данные на нескольких машинах.
– Когда данные хранятся в распределенных системах, таких как HDFS или Amazon S3.
– Когда нужно интегрировать обработку данных с экосистемой Hadoop.
Сравнение Dask и PySpark
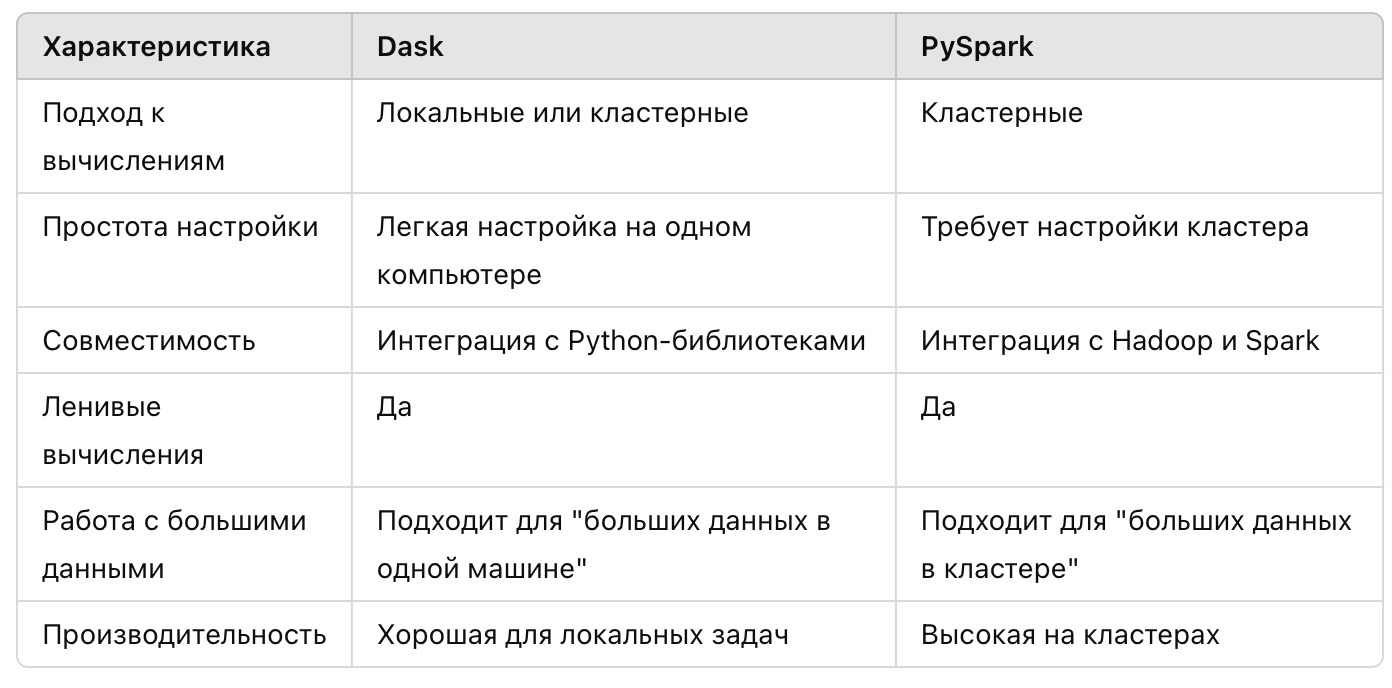
И Dask, и PySpark являются эффективными инструментами для распределенной обработки данных. Выбор между ними зависит от ваших требований. Если вы работаете с данными, которые не помещаются в оперативную память, но ваши вычисления выполняются на одном компьютере, Dask будет лучшим выбором. Если же вы имеете дело с огромными объемами данных, распределенными по нескольким машинам, то PySpark станет незаменимым инструментом.
Обе библиотеки позволяют решать задачи, которые ранее казались невозможными из-за ограничений памяти или производительности, и они помогут вам эффективно работать с данными любого масштаба.
Задачи для практикиЗадачи для Dask
Задача 1: Обработка большого CSV-файла
Описание: У вас есть CSV-файл размером 10 ГБ с данными о продажах. Вам нужно вычислить общую сумму продаж по регионам, но файл слишком большой для работы в Pandas.
Решение:
```python
import dask.dataframe as dd
# Загрузка большого CSV-файла
df = dd.read_csv('sales_data_large.csv')
# Проверка структуры данных
print(df.head()) # Показываем первые строки
# Группировка по регионам и подсчет общей суммы продаж
sales_by_region = df.groupby('region')['sales'].sum()
# Выполнение вычислений
result = sales_by_region.compute()
print(result)
```
Объяснение:
– `dd.read_csv` позволяет загружать файлы большего объема, чем объем оперативной памяти.
– `compute` выполняет ленивые вычисления.
Задача 2: Преобразование данных в формате JSON
Описание: Дан файл в формате JSON, содержащий информацию о транзакциях. Необходимо отфильтровать транзакции с суммой менее 1000 и сохранить отфильтрованные данные в новый CSV-файл.
Решение:
```python
import dask.dataframe as dd
# Загрузка JSON-файла
df = dd.read_json('transactions_large.json')
# Фильтрация данных
filtered_df = df[df['amount'] >= 1000]
# Сохранение результатов в новый CSV-файл
filtered_df.to_csv('filtered_transactions_*.csv', index=False)
print("Данные сохранены в файлы CSV.")
```
Объяснение:
– Dask автоматически разбивает данные на части, сохраняя их в несколько CSV-файлов.
– Фильтрация выполняется параллельно.
Задачи для PySpark
Задача 3: Анализ логов
Описание: Имеется файл логов сервера (формат CSV). Ваша задача – подсчитать количество ошибок (строки с `status = "ERROR"`) и вывести их общее количество.
Решение:
```python
from pyspark.sql import SparkSession
# Создаем сессию Spark
spark = SparkSession.builder.appName("LogAnalysis").getOrCreate()
# Загрузка данных из CSV-файла
df = spark.read.csv('server_logs.csv', header=True, inferSchema=True)
# Фильтрация строк с ошибками
errors = df.filter(df['status'] == 'ERROR')
# Подсчет количества ошибок
error_count = errors.count()
print(f"Количество ошибок: {error_count}")
# Завершаем сессию Spark
spark.stop()
```
Объяснение:
– `filter` позволяет выбрать строки с определенным значением.
– `count` подсчитывает количество строк после фильтрации.
Задача 4: Средняя сумма покупок
Описание: Дан CSV-файл с данными о покупках. Ваша задача – вычислить среднюю сумму покупок для каждого клиента.
Решение:
```python
from pyspark.sql import SparkSession
# Создаем сессию Spark
spark = SparkSession.builder.appName("PurchaseAnalysis").getOrCreate()
# Загрузка данных
df = spark.read.csv('purchases.csv', header=True, inferSchema=True)
# Группировка по клиенту и расчет средней суммы покупок
avg_purchases = df.groupBy('customer_id').avg('purchase_amount')
# Показ результатов
avg_purchases.show()
# Завершаем сессию Spark
spark.stop()
```
Объяснение:
– `groupBy` позволяет сгруппировать данные по столбцу.
– `avg` вычисляет среднее значение для каждой группы.
Задача 5: Сортировка больших данных
Описание: У вас есть файл с информацией о транзакциях. Необходимо отсортировать данные по дате транзакции и сохранить результат в новый файл.
Решение:
```python
from pyspark.sql import SparkSession
# Создаем сессию Spark
spark = SparkSession.builder.appName("SortTransactions").getOrCreate()
# Загрузка данных
df = spark.read.csv('transactions_large.csv', header=True, inferSchema=True)
# Сортировка данных по дате
sorted_df = df.orderBy('transaction_date')
# Сохранение отсортированных данных в новый файл
sorted_df.write.csv('sorted_transactions', header=True, mode='overwrite')
print("Данные отсортированы и сохранены.")
# Завершаем сессию Spark
spark.stop()
```
Объяснение:
– `orderBy` сортирует данные по указанному столбцу.
– `write.csv` сохраняет результат в новом файле.
Эти задачи демонстрируют, как использовать Dask и PySpark для работы с большими объемами данных.
– Dask подходит для локальных задач и интеграции с Python-библиотеками.
– PySpark эффективен для кластерной обработки данных и интеграции с экосистемой Hadoop.
Обе библиотеки упрощают решение задач, которые сложно выполнить традиционными методами из-за ограничений памяти или мощности процессора.
1.2 Потоковая обработка данных с Apache Kafka
Apache Kafka – это мощная платформа для обработки потоков данных в реальном времени. Она широко используется для обработки и анализа событий, поступающих из различных источников, таких как веб-серверы, базы данных, датчики IoT, системы мониторинга и многое другое. Kafka обеспечивает высокую производительность, надежность и масштабируемость, что делает её одним из лучших инструментов для потоковой обработки данных.
В основе Apache Kafka лежат несколько ключевых компонентов:
1. Брокеры – серверы, которые принимают, хранят и доставляют данные.
2. Топики – логические каналы, через которые данные передаются.
3. Продюсеры – приложения или устройства, которые отправляют данные в Kafka.
4. Консьюмеры – приложения, которые получают данные из Kafka.
Kafka организует поток данных в виде последовательностей сообщений. Сообщения записываются в топики и разделяются на партиции, что позволяет обрабатывать данные параллельно.
Пример потока данных
Представим, что у нас есть система интернет-магазина, где Kafka используется для обработки событий, таких как заказы, клики на странице, добавление товаров в корзину и платежи. Каждое из этих событий записывается в топик Kafka. Например, топик `orders` может содержать события, описывающие новые заказы.
Установка и настройка Apache Kafka
Перед началом работы убедитесь, что Kafka установлена. Для локальной работы используйте официальные сборки Kafka с сайта [Apache Kafka](https://kafka.apache.org/).
1. Установите Kafka и запустите ZooKeeper, необходимый для управления брокерами.
2. Запустите Kafka-брокер.
3. Создайте топик с помощью команды:
```bash
bin/kafka-topics.sh –create –topic orders –bootstrap-server localhost:9092 –partitions 3 –replication-factor 1
```
Отправка данных в Kafka
Теперь создадим простого продюсера на Python, который будет отправлять данные в топик `orders`. Для работы с Kafka на Python используется библиотека `confluent-kafka`. Установите её с помощью команды:
```bash
pip install confluent-kafka
```
Пример кода, который отправляет сообщения в топик:
```python
from confluent_kafka import Producer
import json
import time
# Настройки продюсера
producer_config = {
'bootstrap.servers': 'localhost:9092' # Адрес Kafka-брокера
}
# Создание продюсера
producer = Producer(producer_config)
# Функция для обратного вызова при успешной отправке сообщения
def delivery_report(err, msg):
if err is not None:
print(f'Ошибка доставки сообщения: {err}')
else:
print(f'Сообщение отправлено: {msg.topic()} [{msg.partition()}]')
# Отправка данных в Kafka
orders = [
{'order_id': 1, 'product': 'Laptop', 'price': 1000},
{'order_id': 2, 'product': 'Phone', 'price': 500},
{'order_id': 3, 'product': 'Headphones', 'price': 150}
]
for order in orders:
producer.produce(
'orders',
key=str(order['order_id']),
value=json.dumps(order),
callback=delivery_report
)
producer.flush() # Отправка сообщений в брокер
time.sleep(1)
```
В этом примере продюсер отправляет JSON-объекты в топик `orders`. Каждое сообщение содержит данные о заказе.
Чтение данных из Kafka
Теперь создадим консьюмера, который будет читать сообщения из топика `orders`.
```python
from confluent_kafka import Consumer, KafkaException
# Настройки консьюмера
consumer_config = {
'bootstrap.servers': 'localhost:9092',
'group.id': 'order-group', # Группа консьюмеров
'auto.offset.reset': 'earliest' # Начало чтения с первой записи
}
# Создание консьюмера
consumer = Consumer(consumer_config)
# Подписка на топик
consumer.subscribe(['orders'])
# Чтение сообщений из Kafka
try:
while True:
msg = consumer.poll(1.0) # Ожидание сообщения (1 секунда)
if msg is None:
continue
if msg.error():
if msg.error().code() == KafkaException._PARTITION_EOF:
# Конец партиции
continue
else:
print(f"Ошибка: {msg.error()}")
break
# Обработка сообщения
print(f"Получено сообщение: {msg.value().decode('utf-8')}")
except KeyboardInterrupt:
print("Завершение работы…")
finally:
# Закрытие консьюмера
consumer.close()
```
В этом примере консьюмер подключается к Kafka, читает сообщения из топика `orders` и выводит их на экран.
Потоковая обработка данных
Kafka часто используется совместно с платформами потоковой обработки, такими как Apache Spark или Apache Flink, для анализа данных в реальном времени. Однако вы также можете обрабатывать данные прямо в Python.
Например, предположим, что мы хотим обработать события из топика `orders` и рассчитать суммарную стоимость всех заказов:
```python
from confluent_kafka import Consumer
import json
# Настройки консьюмера
consumer_config = {
'bootstrap.servers': 'localhost:9092',
'group.id': 'order-sum-group',
'auto.offset.reset': 'earliest'
}
# Создание консьюмера
consumer = Consumer(consumer_config)
consumer.subscribe(['orders'])
# Суммарная стоимость заказов
total_sales = 0
try:
while True:
msg = consumer.poll(1.0)
if msg is None:
continue
if msg.error():
continue
# Обработка сообщения
order = json.loads(msg.value().decode('utf-8'))
total_sales += order['price']
print(f"Обработан заказ: {order['order_id']}, текущая сумма: {total_sales}")
except KeyboardInterrupt:
print(f"Общая сумма всех заказов: {total_sales}")
finally:
consumer.close()
```
Преимущества использования Kafka
1. Высокая производительность. Kafka поддерживает миллионы событий в секунду благодаря своей архитектуре и использованию партиций.
2. Надежность. Данные хранятся в Kafka до тех пор, пока их не обработают все подписчики.
3. Масштабируемость. Kafka легко масштабируется путем добавления новых брокеров.
4. Универсальность. Kafka поддерживает интеграцию с большинством современных инструментов обработки данных.
Apache Kafka предоставляет мощный набор инструментов для потоковой обработки данных. Используя Python, вы можете легко настроить передачу данных, их обработку и анализ в реальном времени. Это особенно полезно для систем, где требуется высокая производительность и минимальная задержка при обработке больших потоков данных.
Задачи для практики
Задача 1: Фильтрация событий по условию
Описание:
У вас есть топик `clickstream`, содержащий события о кликах на веб-сайте. Каждое событие содержит следующие поля:
– `user_id` – идентификатор пользователя.
– `url` – URL-адрес, на который был клик.
– `timestamp` – время клика.
Ваша задача: создать консьюмера, который будет читать события из Kafka, фильтровать только события с URL-адресами, содержащими слово "product", и сохранять их в новый топик `filtered_clicks`.
Решение:
```python
from confluent_kafka import Producer, Consumer
import json
# Настройки Kafka
broker = 'localhost:9092'
# Создание продюсера для записи в новый топик
producer = Producer({'bootstrap.servers': broker})
def produce_filtered_event(event):
producer.produce('filtered_clicks', value=json.dumps(event))
producer.flush()
# Создание консьюмера для чтения из исходного топика
consumer = Consumer({
'bootstrap.servers': broker,
'group.id': 'clickstream-group',
'auto.offset.reset': 'earliest'
})
consumer.subscribe(['clickstream'])
# Чтение и фильтрация событий
try:
while True:
msg = consumer.poll(1.0)
if msg is None:
continue
if msg.error():
continue
# Преобразуем сообщение из Kafka в Python-объект
event = json.loads(msg.value().decode('utf-8'))
# Фильтруем события с URL, содержащими "product"
if 'product' in event['url']:
print(f"Фильтруем событие: {event}")
produce_filtered_event(event)
except KeyboardInterrupt:
print("Завершение работы.")
finally:
consumer.close()
```
Объяснение:
– Консьюмер читает события из топика `clickstream`.
– Каждое сообщение проверяется на наличие слова "product" в поле `url`.
– Отфильтрованные события отправляются в новый топик `filtered_clicks` через продюсера.
Задача 2: Подсчет количества событий в реальном времени
Описание:
Топик `log_events` содержит логи системы. Каждое сообщение содержит:
– `log_level` (например, "INFO", "ERROR", "DEBUG").
– `message` (текст лога).
Ваша задача: написать программу, которая считает количество событий уровня "ERROR" в реальном времени и каждые 10 секунд выводит их общее количество.
Решение:
```python
from confluent_kafka import Consumer
import time
# Настройки Kafka
broker = 'localhost:9092'
# Создание консьюмера
consumer = Consumer({
'bootstrap.servers': broker,
'group.id': 'log-group',
'auto.offset.reset': 'earliest'
})
consumer.subscribe(['log_events'])
error_count = 0
start_time = time.time()
try:
while True:
msg = consumer.poll(1.0)
if msg is None:
continue
if msg.error():
continue
# Преобразуем сообщение в Python-объект
log_event = json.loads(msg.value().decode('utf-8'))
# Увеличиваем счетчик, если уровень лога "ERROR"
if log_event['log_level'] == 'ERROR':
error_count += 1
# Каждые 10 секунд выводим текущий счетчик
if time.time() – start_time >= 10:
print(f"Количество ошибок за последние 10 секунд: {error_count}")
error_count = 0
start_time = time.time()
except KeyboardInterrupt:
print("Завершение работы.")

