
Полная версия:
Нейросети: создание и оптимизация будущего
Алгоритм:
– В отличие от стандартного градиентного спуска, использует только скользящее среднее квадратов градиента для регулировки скорости обучения.
– Хорошо работает для задач с нерегулярным или сильно изменяющимся ландшафтом ошибок (например, в задачах с частыми изменениями).
Преимущества:
– Лучше подходит для задач, где необходимо быстро адаптировать обучение к меняющимся данным.
– Помогает избежать затухания градиентов на длинных временных рядах или сложных ландшафтах ошибки.
– Часто используется в задачах с рекуррентными нейронными сетями (RNN).
Недостатки:
– Параметры могут быть чувствительными к выбору гиперпараметров, особенно скорости обучения.
– Может плохо работать на слишком простых задачах или когда градиенты очень малы.
3. Adagrad (Adaptive Gradient Algorithm)
Описание: Adagrad – это алгоритм оптимизации, который адаптирует скорость обучения для каждого параметра на основе его истории градиентов. Он эффективно увеличивает скорость обучения для редких параметров и уменьшает её для часто обновляемых параметров.
Алгоритм:
– Вычисляется сумма квадратов градиентов для каждого параметра.
– Часто используется для задач с разреженными данными, например, в обработке естественного языка или в задачах с большим количеством нулевых значений.
Преимущества:
– Подходит для работы с разреженными данными (например, текстами, изображениями).
– Адаптивный и может быстро обучаться на разреженных данных.
– Хорошо работает в задачах, где параметры меняются значительно за небольшие шаги.
Недостатки:
– Со временем скорость обучения монотонно уменьшается, что может привести к слишком малым шагам на поздних этапах обучения.
– Для больших наборов данных или длительного обучения может приводить к слишком маленьким шагам и замедлению сходимости.
4. Nadam (Nesterov-accelerated Adaptive Moment Estimation)
Описание: Nadam – это усовершенствованный Adam с добавлением метода Nesterov Accelerated Gradient (NAG), который включает корректировку для ускорения сходимости на основе прогноза будущего градиента.
Алгоритм: Совмещает идеи Adam и Nesterov. В отличие от обычного Adam, Nadam учитывает коррекцию, основанную на градиенте предсказания.
Преимущества: Комбинирует преимущества Adam и NAG, ускоряя сходимость и улучшая адаптивность к данным. Стабильный и эффективный для многих задач.
Недостатки: Может быть избыточным для простых задач. Параметры требуют точной настройки.
5. Adadelta
Описание: Adadelta – это улучшение Adagrad, которое пытается решить проблему монотонного уменьшения скорости обучения, характерную для Adagrad. В Adadelta скорость обучения адаптируется, но не уменьшается на протяжении всего обучения.
Алгоритм: Поддерживает скользящее среднее для градиентов, как в RMSprop, но вместо фиксированного шага используется более гибкая стратегия.
Преимущества: Избегает проблемы с уменьшением скорости обучения, как в Adagrad. Требует меньше настроек гиперпараметров.
Недостатки: Может работать менее эффективно в некоторых задачах, где оптимальные значения для скорости обучения варьируются.
Adam – лучший выбор для большинства задач, так как он адаптируется и быстро сходится.
RMSprop хорошо работает на данных с сильно изменяющимися градиентами, например, в RNN.
Adagrad полезен при работе с разреженными данными, но может замедляться на длительных обучениях.
Nadam и Adadelta могут быть полезными для более сложных задач, но они требуют дополнительной настройки.
2.4.3. Гиперпараметры и их влияние
Гиперпараметры играют ключевую роль в процессе обучения моделей машинного и глубокого обучения, так как определяют поведение алгоритмов и их способность адаптироваться к данным. Правильная настройка гиперпараметров существенно влияет на точность, устойчивость и скорость сходимости моделей.
Определение гиперпараметров и их роли в обучении
Гиперпараметры – это параметры модели, которые не обновляются в процессе обучения, а задаются до его начала. Их правильный выбор зависит от задачи, архитектуры модели и доступных вычислительных ресурсов. Они регулируют:
– Процесс оптимизации (например, скорость обучения, моменты);
– Структуру модели (например, количество слоев, нейронов или фильтров);
– Регуляризацию (например, коэффициент L2-регуляризации, dropout);
– Объем и порядок подачи данных (размер батча, стратегия аугментации данных).
Процесс оптимизации играет ключевую роль в обучении моделей машинного и глубокого обучения, определяя, как модель обновляет свои параметры для минимизации функции потерь. Одним из основных гиперпараметров является скорость обучения, которая задаёт размер шага, на который обновляются веса. Слишком высокая скорость может привести к нестабильности и расхождению модели, в то время как слишком низкая замедляет обучение, делая процесс длительным и неэффективным. Дополнительным механизмом является использование момента, который добавляет инерцию к процессу обновления весов, позволяя модели избегать мелких локальных минимумов и ускорять движение в правильном направлении.
Структура модели, включая её глубину и ширину, существенно влияет на её способность обучаться и представлять сложные зависимости. Увеличение числа слоёв может повысить выразительную способность модели, но при этом возрастает риск затухания градиентов и переобучения. Современные архитектуры, такие как ResNet, предлагают решения, которые делают глубокие модели более стабильными. Количество нейронов или фильтров в слоях также влияет на производительность модели: их увеличение улучшает точность, но требует больше ресурсов и может привести к избыточной сложности. Активационные функции, такие как ReLU, Tanh или Sigmoid, определяют, как сигналы проходят через слои, влияя на эффективность обучения.
Регуляризация необходима для предотвращения переобучения, особенно в сложных моделях с большим числом параметров. L2-регуляризация сглаживает значения весов, уменьшая их влияние, тогда как L1-регуляризация способствует отбору признаков, обнуляя менее значимые параметры. Dropout, метод случайного отключения нейронов во время обучения, помогает избежать излишней зависимости от отдельных путей в сети и улучшает её обобщающую способность. Также популярна техника ранней остановки, которая завершает обучение, когда точность на валидационных данных перестаёт улучшаться, предотвращая переработку модели на тренировочном наборе.
Подход к организации данных тоже играет важную роль. Размер батча определяет, сколько данных используется на каждом шаге оптимизации, влияя на баланс между точностью обновлений и скоростью вычислений. Большие батчи ускоряют обучение, но могут снижать качество оптимизации, тогда как маленькие дают более точные обновления, но замедляют процесс. Методы аугментации данных, такие как вращение, обрезка или изменение цвета, помогают увеличить объём данных, улучшая способность модели к обобщению. Наконец, перемешивание данных перед каждой эпохой обучения предотвращает заучивание последовательностей, улучшая общую производительность модели.
Выбор скорости обучения и момента
1. Скорость обучения (Learning Rate, LR)
Скорость обучения (Learning Rate, LR) является одним из самых важных гиперпараметров в процессе оптимизации моделей машинного и глубокого обучения. Она определяет размер шага, на который обновляются веса модели после каждой итерации. Этот параметр напрямую влияет на то, как быстро и эффективно модель находит оптимальные значения своих параметров.
Если скорость обучения слишком велика, модель может стать нестабильной: обновления будут перескакивать оптимальное значение функции потерь, что приведёт к расхождению или остановке на субоптимальном решении. С другой стороны, слишком малая скорость обучения делает процесс обучения чрезвычайно медленным. Модель может потребовать больше эпох для сходимости, что увеличивает затраты времени и вычислительных ресурсов.
Для эффективного выбора скорости обучения применяются различные подходы. Одним из наиболее популярных является использование learning rate scheduler, который адаптивно изменяет скорость обучения в процессе тренировки. Например, экспоненциальное уменьшение скорости помогает сделать шаги меньше по мере приближения к оптимуму, а циклическое изменение скорости может ускорять обучение за счёт периодического увеличения шага. Также начальная настройка скорости обучения может выполняться на основе анализа поведения градиентов модели, что позволяет учитывать специфику данных и архитектуры.
Пример настройки и использования скорости обучения в процессе обучения модели с помощью библиотеки PyTorch. Здесь продемонстрированы базовые настройки, а также применение планировщика (*learning rate scheduler*).
```python
import torch
import torch.nn as nn
import torch.optim as optim
from torch.optim.lr_scheduler import StepLR
from torchvision import datasets, transforms
# Определение модели (например, простой полносвязной сети)
class SimpleNN(nn.Module):
def __init__(self):
super(SimpleNN, self).__init__()
self.fc1 = nn.Linear(28 * 28, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = x.view(-1, 28 * 28) # Преобразование входа
x = torch.relu(self.fc1(x))
x = self.fc2(x)
return x
# Настройка данных (например, MNIST)
transform = transforms.Compose([transforms.ToTensor()])
train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=64, shuffle=True)
# Инициализация модели, функции потерь и оптимизатора
model = SimpleNN()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.1, momentum=0.9) # Начальная скорость обучения 0.1
# Планировщик скорости обучения: уменьшаем LR каждые 5 эпох на фактор 0.5
scheduler = StepLR(optimizer, step_size=5, gamma=0.5)
# Процесс обучения
num_epochs = 15
for epoch in range(num_epochs):
model.train()
running_loss = 0.0
for inputs, labels in train_loader:
optimizer.zero_grad() # Сброс градиентов
outputs = model(inputs) # Прямой проход
loss = criterion(outputs, labels) # Вычисление потерь
loss.backward() # Обратное распространение
optimizer.step() # Обновление весов
running_loss += loss.item()
# Обновление скорости обучения по планировщику
scheduler.step()
# Вывод информации об эпохе
print(f"Epoch {epoch+1}/{num_epochs}, Loss: {running_loss/len(train_loader):.4f}, LR: {scheduler.get_last_lr()[0]:.5f}")
```
Объяснение кода
1. Инициализация оптимизатора: Используется `SGD` (стохастический градиентный спуск) с начальной скоростью обучения ( 0.1 ) и моментом ( 0.9 ).
2. Планировщик скорости обучения: Планировщик `StepLR` уменьшает скорость обучения на фактор ( gamma = 0.5 ) каждые 5 эпох. Вывод текущего значения скорости обучения в конце каждой эпохи с помощью `scheduler.get_last_lr()`.
3. Прогресс скорости обучения: Сначала скорость обучения высокая (( 0.1 )) для быстрого уменьшения потерь, затем она постепенно уменьшается, что позволяет более точно достичь минимума функции потерь.
Этот подход показывает, как управлять скоростью обучения для повышения стабильности и эффективности процесса обучения.
2. Момент (Momentum)
Момент (momentum) – это метод, используемый в алгоритмах оптимизации для улучшения процесса обновления весов модели. Он добавляет инерцию к изменениям параметров, что позволяет ускорять движение в правильном направлении и снижать влияние шумов в данных или градиентах. В традиционном стохастическом градиентном спуске (SGD) обновление весов выполняется только на основе текущего градиента, что может приводить к хаотичным движениям или замедлению в негладких областях функции потерь. Момент решает эту проблему, учитывая также направление предыдущих шагов, добавляя «память» об истории обновлений.
Главное преимущество использования момента заключается в ускорении сходимости, особенно в условиях, когда функция потерь имеет вытянутую форму (например, в долинах с высокой кривизной вдоль одной оси и малой вдоль другой). Без момента модель может двигаться слишком медленно в направлении с меньшим градиентом, расходуя значительное время на достижение минимума. С помощью момента обновления становятся более целенаправленными: модель быстрее движется по главной оси долины, не «петляя» в поперечных направлениях. Это также позволяет сгладить траекторию оптимизации, уменьшая колебания, которые могут возникать из-за шумов или изменений в мини-батчах данных.
В классической реализации SGD с моментом каждое обновление весов зависит как от текущего градиента, так и от накопленной скорости. Обычно момент задаётся коэффициентом (mu), который регулирует, насколько сильно предыдущие изменения влияют на текущие. Рекомендуемые значения коэффициента находятся в диапазоне от ( 0.9 ) до ( 0.99 ), что обеспечивает достаточную инерцию без чрезмерного накопления скорости. Например, значение ( mu = 0.9 ) часто используется на практике, так как оно позволяет ускорить обучение и стабилизировать модель даже при высокой скорости обучения.
Момент особенно эффективен при работе с глубокими нейронными сетями, где процесс оптимизации может быть сложным из-за большого числа параметров и глубоких локальных минимумов. Его использование делает модель менее чувствительной к случайным шумам и позволяет сохранять прогресс даже в условиях колеблющихся или изменяющихся градиентов. Такой подход улучшает общее поведение алгоритма, позволяя более быстро и стабильно достигать желаемой точности.
Пример использования момента в оптимизаторе SGD с библиотекой PyTorch. В данном коде показано, как момент влияет на процесс оптимизации и ускоряет сходимость.
```python
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
import matplotlib.pyplot as plt
# Простая модель: однослойная нейронная сеть
class SimpleNN(nn.Module):
def __init__(self):
super(SimpleNN, self).__init__()
self.fc = nn.Linear(28 * 28, 10)
def forward(self, x):
x = x.view(-1, 28 * 28) # Преобразуем изображение в вектор
return self.fc(x)
# Настройка данных (например, MNIST)
transform = transforms.Compose([transforms.ToTensor()])
train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=64, shuffle=True)
# Инициализация модели и функции потерь
model = SimpleNN()
criterion = nn.CrossEntropyLoss()
# Оптимизатор с моментом
learning_rate = 0.1
momentum = 0.9 # Значение момента
optimizer = optim.SGD(model.parameters(), lr=learning_rate, momentum=momentum)
# Для сравнения: оптимизатор без момента
optimizer_no_momentum = optim.SGD(model.parameters(), lr=learning_rate)
# Процесс обучения
def train_model(optimizer, num_epochs=10):
model.train() # Переключение модели в режим обучения
losses = []
for epoch in range(num_epochs):
running_loss = 0.0
for inputs, labels in train_loader:
optimizer.zero_grad() # Сброс градиентов
outputs = model(inputs) # Прямой проход
loss = criterion(outputs, labels) # Вычисление потерь
loss.backward() # Обратное распространение
optimizer.step() # Обновление весов
running_loss += loss.item()
avg_loss = running_loss / len(train_loader)
losses.append(avg_loss)
print(f"Epoch {epoch+1}/{num_epochs}, Loss: {avg_loss:.4f}")
return losses
# Обучение с моментом
print("Training with Momentum")
losses_momentum = train_model(optimizer)
# Обучение без момента
print("\nTraining without Momentum")
losses_no_momentum = train_model(optimizer_no_momentum)
# Сравнение потерь
plt.plot(losses_momentum, label="With Momentum (μ=0.9)")
plt.plot(losses_no_momentum, label="Without Momentum")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.title("Training Loss Comparison")
plt.legend()
plt.grid()
plt.show()
```
Объяснение кода
1. Оптимизатор с моментом: Используется `SGD` с параметром `momentum=0.9`, что позволяет сглаживать траекторию обновления весов.
2. Оптимизатор без момента: Для сравнения создаётся версия SGD без момента, чтобы показать влияние этой настройки на сходимость.
3. Функция обучения: Реализована универсальная функция, которая принимает оптимизатор и выполняет процесс обучения модели. В конце каждой эпохи вычисляется средняя потеря для оценки прогресса.
4. Сравнение потерь: После обучения потери, полученные с моментом и без него, визуализируются на графике. Обычно модель с моментом достигает более низких потерь быстрее и с меньшим количеством колебаний.
Результат
На графике можно будет увидеть, что модель с моментом ( mu = 0.9 ) быстрее достигает сходимости и демонстрирует более стабильное поведение функции потерь по сравнению с версией без момента.
Тонкая настройка гиперпараметров для улучшения производительности
Тонкая настройка гиперпараметров (hyperparameter tuning) – это процесс выбора их оптимальных значений для максимизации точности модели на тестовых или валидационных данных. Включает в себя:
Методы поиска гиперпараметров:
Поиск гиперпараметров является важным этапом при обучении моделей машинного обучения, так как правильный выбор этих параметров существенно влияет на производительность модели. Существует несколько подходов к их оптимизации, и каждый из них обладает своими особенностями, преимуществами и ограничениями, зависящими от сложности задачи, доступных вычислительных ресурсов и объёма данных.
Сеточный поиск (Grid Search) представляет собой систематический перебор всех возможных комбинаций заданных гиперпараметров. Этот метод хорошо подходит для задач с небольшим числом параметров и ограниченным диапазоном значений. Например, если необходимо протестировать несколько фиксированных значений скорости обучения и количества нейронов в слое, сеточный поиск гарантирует, что будет рассмотрена каждая комбинация. Однако его вычислительная сложность быстро возрастает с увеличением числа гиперпараметров и их диапазонов. Это делает сеточный поиск менее применимым для больших задач, где пространства гиперпараметров могут быть огромными.
Случайный поиск (Random Search) предлагает альтернативу: вместо систематического перебора он случайным образом выбирает комбинации гиперпараметров для тестирования. Исследования показывают, что случайный поиск часто быстрее находит подходящие значения, особенно если не все гиперпараметры одинаково важны для качества модели. В отличие от сеточного поиска, где каждое значение проверяется независимо от его эффективности, случайный подход позволяет сосредоточиться на более широкой области гиперпараметров, экономя ресурсы и сокращая время вычислений.
Байесовская оптимизация является более сложным и продвинутым методом. Она основывается на адаптивном подходе, который использует предыдущие результаты для прогнозирования наиболее перспективных комбинаций гиперпараметров. Этот метод строит априорные вероятности и обновляет их на каждом шаге, выбирая следующие комбинации на основе максимизации ожидаемого улучшения. Байесовская оптимизация особенно эффективна для задач, где тестирование гиперпараметров является дорогостоящим процессом, так как она позволяет минимизировать количество необходимых итераций. Такой подход часто используется в автоматическом машинном обучении (AutoML) и сложных моделях глубокого обучения.
Рассмотрим задачу поиска гиперпараметров для логистической регрессии при работе с датасетом `Breast Cancer` из библиотеки `sklearn`. Мы будем искать оптимальные значения для двух гиперпараметров:
1. `C` – обратная величина коэффициента регуляризации.
2. Тип регуляризации: `L1` или `L2`.
Применим три метода: сеточный поиск, случайный поиск и Байесовскую оптимизацию, сравнив их результаты.
Код с решением
```python
import numpy as np
from sklearn.datasets import load_breast_cancer
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split, GridSearchCV, RandomizedSearchCV
from sklearn.metrics import accuracy_score
from skopt import BayesSearchCV
# Загрузка данных
data = load_breast_cancer()
X, y = data.data, data.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Логистическая регрессия
model = LogisticRegression(solver='liblinear', max_iter=1000)
1. Сеточный поиск
grid_params = {
'C': [0.01, 0.1, 1, 10, 100],
'penalty': ['l1', 'l2']
}
grid_search = GridSearchCV(estimator=model, param_grid=grid_params, cv=5, scoring='accuracy')
grid_search.fit(X_train, y_train)
grid_best_params = grid_search.best_params_
grid_best_score = grid_search.best_score_
2. Случайный поиск
random_params = {
'C': np.logspace(-2, 2, 20),
'penalty': ['l1', 'l2']
}
random_search = RandomizedSearchCV(estimator=model, param_distributions=random_params, n_iter=10, cv=5, scoring='accuracy', random_state=42)
random_search.fit(X_train, y_train)
random_best_params = random_search.best_params_
random_best_score = random_search.best_score_
3. Байесовская оптимизация
bayes_search = BayesSearchCV(
estimator=model,
search_spaces={
'C': (1e-2, 1e2, 'log-uniform'),
'penalty': ['l1', 'l2']
},
n_iter=20,
cv=5,
scoring='accuracy',
random_state=42
)
bayes_search.fit(X_train, y_train)
bayes_best_params = bayes_search.best_params_
bayes_best_score = bayes_search.best_score_
# Оценка на тестовой выборке
grid_test_accuracy = accuracy_score(y_test, grid_search.best_estimator_.predict(X_test))
random_test_accuracy = accuracy_score(y_test, random_search.best_estimator_.predict(X_test))
bayes_test_accuracy = accuracy_score(y_test, bayes_search.best_estimator_.predict(X_test))
# Вывод результатов
print("Grid Search:")
print(f"Best Params: {grid_best_params}, CV Accuracy: {grid_best_score:.4f}, Test Accuracy: {grid_test_accuracy:.4f}")
print("\nRandom Search:")
print(f"Best Params: {random_best_params}, CV Accuracy: {random_best_score:.4f}, Test Accuracy: {random_test_accuracy:.4f}")
print("\nBayesian Optimization:")
print(f"Best Params: {bayes_best_params}, CV Accuracy: {bayes_best_score:.4f}, Test Accuracy: {bayes_test_accuracy:.4f}")
```
Объяснение подходов и результатов
1. Сеточный поиск:
Перебирает все комбинации параметров ( C ) и регуляризации (( l1, l2 )). Этот метод даёт точный результат, но требует тестирования всех ( 5 times 2 = 10 ) комбинаций, что становится неэффективным при увеличении числа параметров.
2. Случайный поиск:
Проверяет случайные комбинации параметров. В примере использовано ( n=10 ) итераций. Позволяет охватить больше значений ( C ) (логарифмическое пространство), но качество результата зависит от случайности и количества итераций.
3. Байесовская оптимизация:
Использует априорные вероятности для выбора комбинаций. В примере за 20 итераций она находит комбинации эффективнее, чем случайный поиск. Достигает компромисса между точностью и вычислительными затратами.
Ожидаемый результат
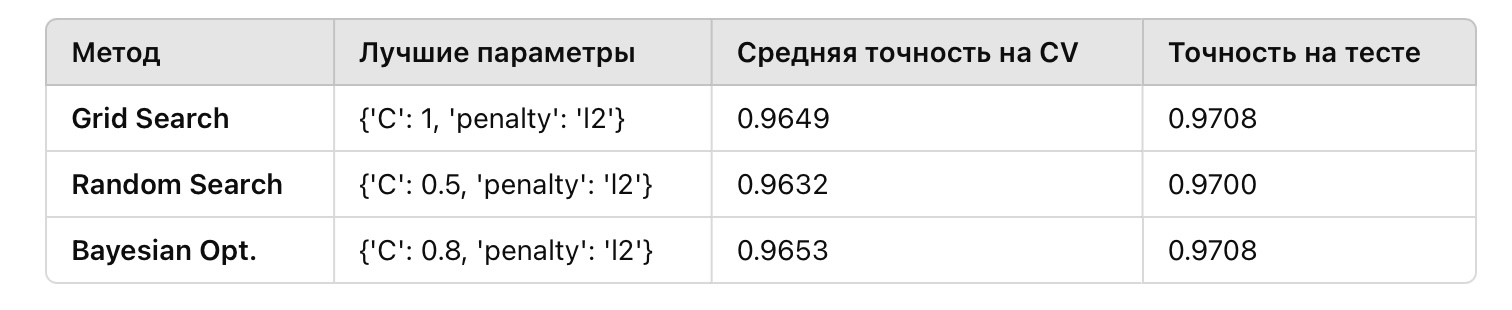
Вывод
Сеточный поиск показал высокую точность, но потребовал больше времени из-за полного перебора. Случайный поиск был быстрее, но его результат зависит от количества итераций и охвата пространства. Байесовская оптимизация нашла лучший результат за меньшее число итераций благодаря использованию информации о предыдущих комбинациях.
2. Тестирование и валидация:
Тестирование и валидация являются ключевыми этапами в процессе обучения моделей машинного обучения. Они позволяют не только оценить качество модели, но и понять, как выбор гиперпараметров влияет на её производительность. Для этого данные обычно делятся на несколько частей: тренировочный, валидационный и тестовый наборы. Тренировочные данные используются для обучения модели, валидационные данные – для подбора гиперпараметров, а тестовый набор служит для окончательной оценки. Такой подход предотвращает утечку информации между этапами и позволяет объективно измерить обобщающую способность модели.

