
Полная версия:
Глоссариум по искусственному интеллекту: 2500 терминов. Том 1

Глоссариум по искусственному интеллекту: 2500 терминов
Том 1
Александр Юрьевич Чесалов
Александр Николаевич Власкин
Матвей Олегович Баканач
Редактор Хаджимурад Ахмедович Магомедов
Дизайнер обложки Александр Юрьевич Чесалов
Иллюстратор Александр Юрьевич Чесалов
Корректор Александр Хафизович Юлдашев
© Александр Юрьевич Чесалов, 2024
© Александр Николаевич Власкин, 2024
© Матвей Олегович Баканач, 2024
© Александр Юрьевич Чесалов, дизайн обложки, 2024
© Александр Юрьевич Чесалов, иллюстрации, 2024
ISBN 978-5-0056-8677-0
Создано в интеллектуальной издательской системе Ridero
От Авторов-составителей
Александр Юрьевич Чесалов,
Власкин Александр Николаевич,
Баканач Матвей Олегович
Эксперты по информационным технологиям и искусственному интеллекту, разработчики программы Центра искусственного интеллекта МГТУ им. Н. Э. Баумана, программы «Искусственный интеллект» и «Глубокая аналитика» проекта «Приоритет 2030» МГТУ им. Н. Э. Баумана в 2021—2022 годах.
Дорогие Друзья и Коллеги!
Авторы составители этой книги посвятили подготовке и созданию данного глоссария (краткого словаря специализированных терминов) два года.
«Пилотная» версия книги была подготовлена всего за восемь месяцев и представлена на на 35-ой Московской международной книжной ярмарке в 2022 году.
В какой-то момент времени книга выросла до восьми ста шестидесяти страниц и нам пришлось подготовить двухтомное издание.
Сейчас мы рады представить Вам первый том книги, который содержит более тысячи двух сот пятидесяти терминов и определений по искусственному интеллекту на русском языке.
Изображение обложки к книге нарисовано в системе генеративного искусственного интеллекта Easy Diffusion.

35-ая Московская международная книжная ярмарка в 2022 году. С лева направо Александр Чесалов, Александр Власкин и Матвей Баканач
Почему книга называется «Глоссариум»?
«Glossarium» на латинском языке означает словарь узкоспециализированных терминов.
Идея составления «глоссариев» принадлежит одному из соавторов книги – Александру Чесалову. Первый его опыт в этой области был в составлении глоссария по искусственному интеллекту и информационным технологиям, который он опубликовал в декабре 2021 года.1 В нем первоначально было всего 400 терминов. Затем, уже в 2022 году, Александр его существенно расширил до более чем 1000 актуальных терминов и определений. Впоследствии он опубликовал целую серию книг, раскрывающих темы четвертой промышленной революции, цифровой экономики, цифрового здравоохранения и многих других.
Идея создания большого глоссария по искусственному интеллекту родилась в начале 2022 года. Авторы пришли к единодушному решению объединить свои усилия и свой опыт последних лет в области искусственного интеллекта, который был подкреплен несколькими знаменательными и судьбоносными событиями.
Несомненно, самое существенное событие, которое произошло несколько ранее в 2021 году – это участие авторов (как экспертов) в Конкурсе, проводимом Аналитическим Центром при Правительстве России по отбору получателей поддержки исследовательских центров в сфере искусственного интеллекта, в том числе в области «сильного» искусственного интеллекта, систем доверенного искусственного интеллекта и этических аспектов применения искусственного интеллекта. Перед нами стояла неординарная и еще на тот момент времени никем не решенная задача создания Центра разработки и внедрения сильного и прикладного искусственного интеллекта МГТУ им. Н. Э. Баумана. Все авторы этой книги приняли самое непосредственное участие в разработке и написании программы и плана мероприятий нового Центра. Подробнее об этой истории можно узнать из книги Александра Чесалова «Как создать центр искусственного интеллекта за 100 дней».
Далее мы приняли участие в Первом международном форуме «Этика искусственного интеллекта: начало доверия», который состоялся 26 октября 2021 года и в рамках которого была организована церемония торжественного подписания Национального кодекса этики искусственного интеллекта, устанавливающего общие этические принципы и стандарты поведения, которыми следует руководствоваться участникам отношений в сфере искусственного интеллекта в своей деятельности. По сути, форум стал первой в России специализированной площадкой, где собралось около полутора тысяч разработчиков и пользователей технологий искусственного интеллекта.
В дополнение ко всему мы не прошли мимо и Международной конференции по искусственному интеллекту и анализу данных AI Journey, в рамках которой 10 ноября 2021 года к подписанию Национального Кодекса этики искусственного интеллекта присоединились лидеры ИТ-рынка. Число спикеров конференции поражало воображение – их было более двухсот, а число онлайн-посещений сайта более сорока миллионов.
Уже в 2022 году мы приняли самое активное участие в Международном военно-техническом форуме «Армия-2022» с докладом «Разработка программно-аппаратных комплексов для решения широкого круга прикладных задач с использованием технологий машинного обучения и доверенного искусственного интеллекта в Оборонно-промышленном комплексе РФ».
Резюмируя всю нашу активную работу за последние пару лет и тот опыт, который был уже накоплен, мы пришли к необходимости систематизировать накопленные знания и изложить их в новой книге, которую вы держите в своих руках.
Мы часто с вами слышим «искусственный интеллект».
Но понимаем ли мы что это такое?
Например, в этой книге мы зафиксировали, что Искусственный интеллект – это компьютерная система, основанная на комплексе научных и инженерных знаний, а также технологий создания интеллектуальных машин, программ, сервисов и приложений, имитирующая мыслительные процессы человека или живых существ, способная с определенной степенью автономности воспринимать информацию, обучаться и принимать решения на основе анализа больших массивов данных, целью создания которой является помощь людям в решении их повседневных рутинных задач.
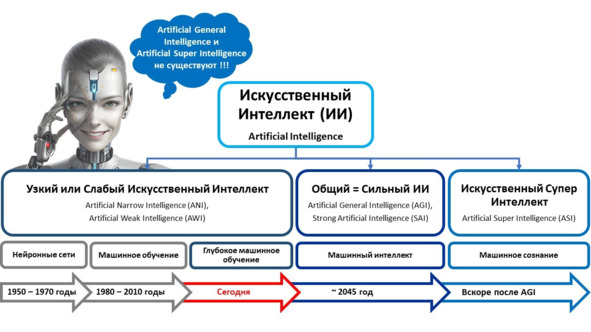
Или, еще один пример.
Что такое «доверенный искусственный интеллект»?
Системой доверенного искусственного интеллекта называют прикладную систему искусственного интеллекта, обеспечивающую выполнение возложенных на нее задач с учетом ряда дополнительных требований, учитывающих этические аспекты применения искусственного интеллекта, которая обеспечивает доверие к результатам ее работы, которые, в свою очередь, включают в себя: достоверность (надежность) и интерпретируемость выводов и предлагаемых решений, полученных с помощью системы и проверенных на верифицированных тестовых примерах; безопасность как с точки зрения невозможности причинения вреда пользователям системы на протяжении всего жизненного цикла системы, так и с точки зрения защиты от взлома, несанкционированного доступа и других негативных внешних воздействий, приватность и проверяемость данных, с которыми работают алгоритмы искусственного интеллекта, включая разграничение доступа и другие связанные с этим вопросы.
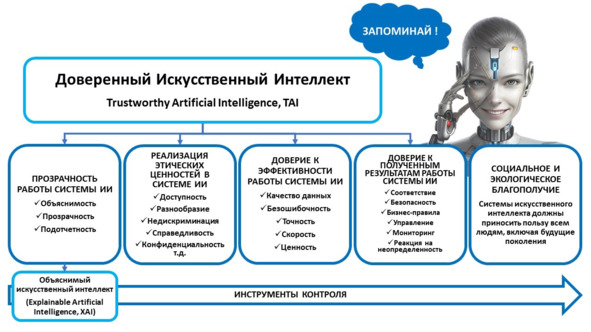
А что же тогда такое «машинное обучение»?
Машинное обучение – это одно из направлений (подмножеств) искусственного интеллекта, благодаря которому воплощается ключевое свойство интеллектуальных компьютерных систем – самообучение на основе анализа и обработки больших разнородных данных. Чем больше объем информации и ее разнообразие, тем проще искусственному интеллекту найти закономерности и тем точнее будет получаемый результат.
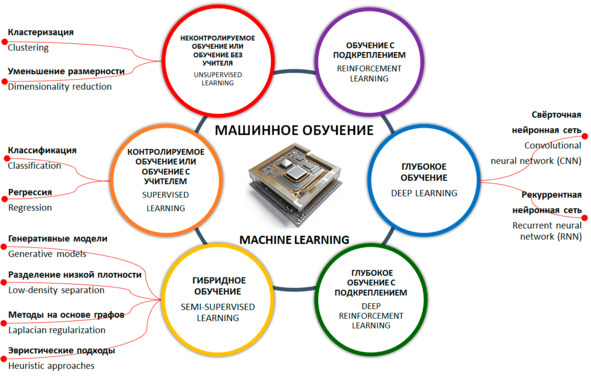
Чтобы заинтересовать уважаемого читателя, приведем еще несколько «забавных» примеров.
Слышали ли вы когда-нибудь о «Трансгуманистах»?
С одной стороны, как идея Трансгуманизм (Transhumanism) – это расширение возможностей человека с помощью науки. С другой стороны – это философская концепция и международное движение, приверженцы которого желают стать «постлюдьми» и преодолеть всевозможные физические ограничения, болезни, душевные страдания, старость и смерть благодаря использованию возможностей нано- и био- технологий, искусственного интеллекта и когнитивной науки.
На наш взгляд, идеи «трансгуманизма» очень тесно пересекаются с идеями и концепциями «цифрового человеческого бессмертия».

TEDx ForestersPark 2019 год
Несомненно, вы слышали и конечно знаете, кто такой «Data Scientist» – ученый и специалист по работе с данными.
А слышали ли вы когда-нибудь о «датасатанистах»? :-)
Датасатанисты – это определение, придуманное авторами, но отражающее современную действительность (наравне, например, с термином «инфоцыганщина»), которая сформировалась в период популяризации и повсеместной реализации идей искусственного интеллекта в современном информационном обществе. По своей сути датасатанисты – это мошенники и преступники, которые очень умело маскируются под ученых и специалистов в области ИИ и МО, но при этом пользуются чужими заслугами, знаниями и опытом, в своих корыстных целях и целях незаконного обогащения.
А, как вам такой термин – «библеоклазм»?
Библиоклазм – человек, в силу своего трансформированного мировоззрения и чрезмерно раздутого эго, из зависти или какой-либо другой корыстной цели, который стремится уничтожить книги других авторов. Вы не поверите, но таких людей, как «датасатанисты» или «библиоклазмы» сейчас достаточно.
А, как вам такие термины: «искусственная жизнь», «искусственный сверхинтеллект», «нейроморфный искусственный интеллект», «человеко-ориентированный искусственный интеллект», «синтетический интеллект», «распределенный искусственный интеллект», «дружественный искусственный интеллект», «дополненный искусственный интеллект», «композитный искусственный интеллект», «объяснимый искусственный интеллект», «причинно-следственный искусственный интеллект», «символический искусственный интеллект» и многие другие (все они есть в этой книге).
Таких примеров «удивительных» терминов мы можем привести еще не мало. Но в своей работе мы не стали тратить время на «суровую действительность» и сместили акцент на конструктивный и позитивный настрой. Одним словом, мы провели для Вас большую работу и собрали более 2500 терминов и определений по машинному обучению и искусственному интеллекту на основе своего опыта и данных из огромного числа различных источников.
2500 терминов и определений.
Много это или мало?
Наш опыт подсказывает, что для взаимопонимания двум собеседникам достаточно знать десяток или, максимум, два десятка определений. Но, когда дело касается профессиональной деятельности, то может получиться так, что мало знать, даже, несколько десятков терминов.
В этой книге приведены самые актуальные термины и определения, по-нашему мнению, наиболее часто употребляемые, как в повседневной работе, так и профессиональной деятельности специалистами самых разных профессий, интересующихся темой «искусственного интеллекта».
Мы очень старались сделать для вас нужный и полезный «инструмент» для вашей работы.
В заключение хочется добавить и проинформировать уважаемого читателя о том, что эта книга является абсолютно открытым и свободным к распространению документом. В случае, если Вы используете ее в своей практической работе, просим Вас делать ссылку на нее.
Многие из терминов и определений к ним, в этой книге, встречаются в сети Интернет. Они повторяются десятки или сотни раз на различных информационных ресурсах (в основном на зарубежных). Тем не менее, мы поставили перед собой цель – собрать и систематизировать самые актуальные из них в одном месте из самых разных источников, нужные из них перевести на русский язык и/или адаптировать, а какие-то и написать заново, исходя из собственного опыта.
Учитывая вышесказанное, мы не претендуем на авторство или уникальность представленных терминов и определений, но, несомненно, мы внесли свой собственный вклад в систематизацию и адаптацию многих из них.
Книга написана, прежде всего, для вашего удовольствия.
Мы продолжаем работу по улучшению качества и содержания текста этой книги, в том числе дополняем ее новыми знаниями по предметной области. Будем вам благодарны за любые отзывы, предложения и уточнения. Направляйте их, пожалуйста, на aleksander.chesalov@yandex.ru
Приятного Вам чтения и продуктивной работы!
Ваши, Александр Чесалов, Александр Власкин и Матвей Баканач.
16.08.2022. Издание первое.
09.03.2023. Издание второе. Исправленное и дополненное.
01.01.2024. Издание третье. Исправленное и дополненное.

Глоссариум по искусственному интеллекту
«А»
А/B-тестирование, также известное как сплит-тестирование (A/B Testing) – это процесс экспериментирования, при котором две или более версии переменной (веб-страницы, элемента страницы и т.д.) одновременно демонстрируются разным сегментам посетителей веб-сайта, чтобы определить, какая версия оказывает максимальное влияние и повышает бизнес-показатели2.
Абдуктивное логическое программирование (Abductive logic programming, ALP) – это высокоуровневая структура представления знаний, которая может использоваться для решения проблем декларативно – на основе абдуктивного рассуждения. Она расширяет нормальное логическое программирование, позволяя некоторым предикатам быть неполно определенными, объявленными как абдуктивные предикаты3.
Абдукция (Abductive reasoning) – (от латинского ab – «c, от», ducere – «водить») – это форма логического вывода, которая начинается с наблюдения или набора наблюдений, а затем пытается найти самое простое и наиболее вероятное объяснение. Этот процесс, в отличие от дедуктивного рассуждения, дает правдоподобный вывод, но не подтверждает его основаниями для вывода4.
Абстрактный тип данных (Abstract data type) – это математическая модель для типов данных, где тип данных определяется поведением (семантикой) с точки зрения пользователя, а именно в терминах возможных значений, возможных операций над данными этого типа и поведения этих операций. Формально АТД может быть определён как множество объектов, определяемое списком компонентов (операций, применимых к этим объектам, и их свойств)5.
Абстракция (Abstraction) – это использование только тех характеристик объекта, которые с достаточной точностью представляют его в данной системе. Основная идея состоит в том, чтобы представить объект минимальным набором полей и методов и при этом с достаточной точностью для решаемой задачи6.
Автоассоциативная память (Auto Associative Memory) – это однослойная нейронная сеть, в которой входной обучающий вектор и выходные целевые векторы совпадают. Веса определяются таким образом, чтобы сеть хранила набор шаблонов. Как показано на следующем рисунке, архитектура сети автоассоциативной памяти имеет «n» количество входных обучающих векторов и аналогичное «n» количество выходных целевых векторов7.
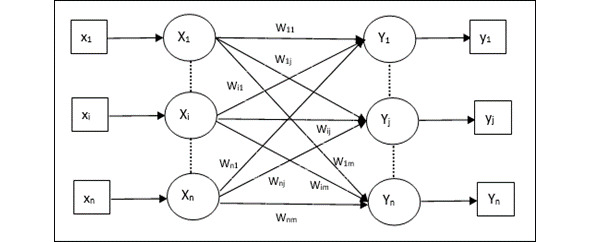
Автокодер (Автоэнкодер) (Autoencoder, AE) – это нейронная сеть, которая копирует входные данные на выход. По архитектуре похож на персептрон. Автоэнкодеры сжимают входные данные для представления их в latent-space (скрытое пространство), а затем восстанавливают из этого представления output (выходные данные). Цель – получить на выходном слое отклик, наиболее близкий к входному. Отличительная особенность автоэнкодеров – количество нейронов на входе и на выходе совпадает8.
Автоматизация (Automation) – это технология, с помощью которой процесс или процедура выполняется с минимальным участием человека9.
Автоматизированная обработка персональных данных (Automated processing of personal data) – это обработка персональных данных с помощью средств вычислительной техники10.
Автоматизированная система (Automated system) – это организационно-техническая система, которая гарантирует выработку решений, основанных на автоматизации информационных процессов во всевозможных отраслях деятельности11.
Автоматизированная система управления (Automated control system) – это комплекс программных и программно-аппаратных средств, предназначенных для контроля за технологическим и (или) производственным оборудованием (исполнительными устройствами) и производимыми ими процессами, а также для управления такими оборудованием и процессами12.
Автоматизированное мышление (Automated reasoning) – это область информатики, которая занимается применением рассуждений в форме логики к вычислительным системам. Если задан набор предположений и цель, автоматизированная система рассуждений должна быть способна автоматически делать логические выводы для достижения этой цели13.
Автономное транспортное средство (Autonomous vehicle) – это вид транспорта, основанный на автономной системе управления. Управление автономным транспортным средством полностью автоматизировано и осуществляется без водителя при помощи оптических датчиков, радиолокации и компьютерных алгоритмов14.
Автономность (Autonomous) – это способность машины выполнять свою задачу без вмешательства и контроля человека15.
Автономные вычисления (Autonomic computing) – это способность системы к адаптивному самоуправлению собственными ресурсами для высокоуровневых вычислительных функций без ввода данных пользователем16.
Автономный автомобиль (Autonomous car) – это транспортное средство, способное воспринимать окружающую среду и работать без участия человека. Пассажир-человек не обязан брать на себя управление транспортным средством в любое время, и пассажиру-человеку вообще не требуется присутствовать в транспортном средстве. Автономный автомобиль может проехать везде, где ездит традиционный автомобиль, и делать все то же, что и опытный водитель-человек17.
Автономный вывод (Offline inference) – это генерация группы прогнозов, сохранение этих прогнозов, а затем извлечение этих прогнозов по запросу18.
Автономный искусственный интеллект (Autonomous artificial intelligence) – это биологически инспирированная система, которая пытается воспроизвести устройство мозга, принципы его действия со всеми вытекающими отсюда свойствами19,20.
Автономный робот (Autonomous robot) – это робот, который спроектирован и сконструирован так, чтобы самостоятельно взаимодействовать с окружающей средой и работать в течение длительных периодов времени без вмешательства человека. Автономные роботы часто обладают сложными функциями, которые могут помочь им воспринимать физическое окружение и автоматизировать действия и процессы, которые раньше выполнялись руками человека21.
Авторегрессионная модель (Autoregressive Model) – это модель временного ряда, в которой наблюдения за предыдущими временными шагами используются в качестве входных данных для уравнения регрессии для прогнозирования значения на следующем временном шаге. В статистике и обработке сигналов авторегрессионная модель представляет собой тип случайного процесса. Он используется для описания некоторых изменяющихся во времени процессов в природе, экономике и т.д.22.
Агент (Agent) в обучении с подкреплением – это испытуемая система, которая обучается и взаимодействует с некоторой средой. Агент воздействует на среду, а среда воздействует на агента23.
Агрегат (Aggregate) – это сумма, созданная из более мелких единиц. Например, население области – это совокупность населения городов, сельских районов и т.д., входящих в состав области. Суммировать данные из меньших единиц в большую единицу24.
Агрегатор (Aggregator) – это тип программного обеспечения, которое объединяет различные типы веб-контента и предоставляет его в виде легкодоступного списка. Агрегаторы каналов собирают такие данные, как онлайн-статьи из газет или цифровых изданий, публикации в блогах, видео, подкасты и т. д. Агрегатор каналов также известен как агрегатор новостей, программа для чтения каналов, агрегатор контента или программа для чтения RSS25.
Агломеративная кластеризация (Agglomerative clustering) – это один из алгоритмов кластеризации, в котором процесс группировки похожих экземпляров начинается с создания нескольких групп, где каждая группа содержит один объект на начальном этапе, затем он находит две наиболее похожие группы, объединяет их, повторяет процесс до тех пор, пока не получит единую группу наиболее похожих экземпляров26.
Адаптивная система (Adaptive system) – это система, которая автоматически изменяет данные алгоритма своего функционирования и (иногда) свою структуру для поддержания или достижения оптимального состояния при изменении внешних условий27.
Адаптивная система нейро-нечеткого вывода (Adaptive neuro fuzzy inference system) (ANFIS) (также адаптивная система нечеткого вывода на основе сети) – это разновидность искусственной нейронной сети, основанная на системе нечеткого вывода Такаги-Сугено. Методика была разработана в начале 1990-х годов. Поскольку она объединяет как нейронные сети, так и принципы нечеткой логики, то может использовать одновременно все имеющиеся преимущества в одной структуре. Его система вывода соответствует набору нечетких правил ЕСЛИ-ТО, которые имеют возможность обучения для аппроксимации нелинейных функций. Следовательно, ANFIS считается универсальной оценочной функцией. Для более эффективного и оптимального использования ANFIS можно использовать наилучшие параметры, полученные с помощью генетического алгоритма28.
Адаптивный алгоритм (Adaptive algorithm) – это алгоритм, который пытается выдать лучшие результаты путём постоянной подстройки под входные данные. Такие алгоритмы применяются при сжатии без потерь. Классическим вариантом можно считать Алгоритм Хаффмана29,30.
Адаптивный градиентный алгоритм (Adaptive Gradient Algorithm) (AdaGrad) – это cложный алгоритм градиентного спуска, который перемасштабирует градиент отдельно на каждом параметре, эффективно присваивая каждому параметру независимый коэффициент обучения31.
Аддитивные технологии (Additive technologies) – это технологии послойного создания трехмерных объектов на основе их цифровых моделей («двойников»), позволяющие изготавливать изделия сложных геометрических форм и профилей32.
Айзек Азимов (Isaac Asimov) (1920—1992) – автор научной фантастики, сформулировал три закона робототехники, которые продолжают оказывать влияние на исследователей в области робототехники и искусственного интеллекта (ИИ)33.
Три закона робототехники Айзека Азимова (Three Laws of Robotics by Isaac Asimov) – Робот не может причинить вред человеку или своим бездействием допустить, чтобы человеку был причинен вред. Робот должен подчиняться приказам, отданным ему людьми, за исключением случаев, когда такие приказы противоречат Первому закону. Робот должен защищать свое существование до тех пор, пока такая защита не противоречит Первому или Второму закону34.
Активное обучение/Стратегия активного обучения (Active Learning/ Active Learning Strategy) – это особый способ полууправляемого машинного обучения, в котором обучающий агент может в интерактивном режиме запрашивать оракула (обычно человека-аннотатора) для получения меток в новых точках данных. Подход к такому обучению основывается на самостоятельном выборе алгоритма некоторых данных из массы тех, на которых он учится. Активное обучение особенно ценно, когда помеченных примеров мало или их получение слишком затратно. Вместо слепого поиска разнообразных помеченных примеров алгоритм активного обучения выборочно ищет конкретный набор примеров, необходимых для обучения35,36,37.

