
Полная версия:
КонтрПлагиат методом перефразирования и рерайта для антиплагиат ВУЗ. Как повысить оригинальность текста за несколько часов и пройти проверку с первого раза

КонтрПлагиат методом перефразирования и рерайта для антиплагиат ВУЗ
Как повысить оригинальность текста за несколько часов и пройти проверку с первого раза
Вячеслав Алексеевич Мустакимов
Алексей Вячеславович Мустакимов
© Вячеслав Алексеевич Мустакимов, 2024
© Алексей Вячеславович Мустакимов, 2024
ISBN 978-5-0064-3068-6
Создано в интеллектуальной издательской системе Ridero
Введение
Актуальность настоящей работы обусловлена тем, что сегодня многие авторы письменных работ обладают умением находить в Интернете нужные тексты, копировать найденное и вставлять в свои работы. С оптимизационной точки зрения автора, желательно копировать большие куски, в идеале, целые параграфы. Авторская «оптимизация» написания работ, в итоге, приводит к дефициту оригинальности текста. По нашим статистическим заключениям, средний процент уникальности написанной работы колеблется в диапазоне 10—30%, а для успешного прохождения антиплагиат проверки требуется 70—80%. Исходя из этого, процесс написания любой академической работы содержит выраженные стадии: сборка работы (компиляция) и повышение уникальности (перефразирование, рерайт). Данная стадийность условная, но для цели нашего исследования вполне приемлемая.
Понятие «рерайт» не является сакральным, однако понимание «легкого», «поверхностного» и «глубокого» рерайта, перефразирования – ускользает, нам не удалось найти исчерпывающего объяснения такого отличия, причем, выраженного числовыми, измеримыми показателями, раз уж мы говорим о экспертизе научных работ на плагиат.
Для выявления уровня оригинальности академических и научных работ имеется масса сервисов, готовых заработать на поиске плагиата: Copyscape, Grammarly, HelioBLAST, iThenticate, PlagScan, PlagTracker, Turnitin, Unicheck, StrikePlagiarism, ETXT, text, РуКонтекст, antiplagiat и т. д. В силу отсутствия измеримости показателя рерайта, как отличия текста источника и текста после рерайта, каждый сервис изобретает собственные критерии, и клиентская общность оперирует такими понятиями, как «жесткая» и «мягкая» проверка. Эта «экспертная» сумятица вносит определённый хаос, т.к. блестяще пройденная проверка на плагиат в одном сервисе, покажет «уникальную несостоятельность» работы в другом сервисе.
Поиск текстовых заимствований в России – повторение опыта зарубежных коллег, в 2005 году в нашей стране был введен надзорный инструмент под названием «Антиплагиат», который сформировал динамично растущий рынок рерайтинга (перефразирования). Сегодня антиплагиат известен под разными именами, само понятие антиплагиат – явление проверки на уникальность (оригинальность), а антиплагиат, расположенный на домене ру, он же ВУЗ, – это упоминание конкретного сервиса antiplagiat, на указанном домене.
Уточняя терминологию, отметим, что КонтрПлагиат – это специальные меры, направленные на исключение из текстов плагиата (заимствований), включающих перефразирование, глубокий рерайт и копирайтинг, а также комплекс нетрадиционных для рерайта методов, отграниченных от обычной практики, принятой в «научном письме». Главное отличие КонтрПлагиата от традиционного рерайта и копирайтинга – его доказательность и прогнозируемость результатов, другими словами, текст изменяется не с «поверхностным, мягким» или «глубоким» отличием, а на нормированное значение, и в статистическом большинстве это нормированное изменение текста дает высокий и необходимый процент при проверке в системах антиплагиат.
КонтрПлагиат оперирует двумя терминами, шингл – словосочетание из двух слов, например – «Внимание, документ подозрительный: в документе присутствует сгенерированный текст», фраза содержит следующие шинглы: «Внимание, документ», «документ подозрительный», «подозрительный в», «в документе», «документе присутствует», «присутствует сгенерированный», «сгенерированный текст». Иллюстрация понятия шингла утрирована, т.к. шингл учитывает текстовое содержание без предлогов и стоп-слов, в лемматизированной форме.
N-грамма, в упрощенном понимании, это словосочетание из нескольких слов, например: «Внимание, документ», «подозрительный: в», «документе присутствует», «сгенерированный текст». В примере выделены биграммы, которые следуют друг за другом, триграммы будут состоять из трех слов и т. д.
КонтрПлагиат, не новация, предусматривает активное использование как традиционных методов, так и современных информационных решений и технологий, таких как генеративный искусственный интеллект (ИИ), способный генерировать текст в ответ на подсказки (инструкции). Наравне с перечисленными методами используются малоизвестные методики, бесплатные, но эффективные, позволяющие выдавать большую уникальность текста, нежели этого требуют «жесткие» проверки. В отличии от сервисов поиска заимствований, КонтрПлагиат поясняет содержание и критерии понятия «жесткая» проверка, позволяет измерять параметры локально, а при достижении критериев документ отдается на антиплагиат проверку, что позволяет пройти ее с первого раза.
В практике высшей школы написание письменных работ тоже не новация, и этим занимаются веками как студенты, так и их преподаватели. Классика компилятивного метода (см. Умберто Эко) гласит, что работа составляется из материалов, добросовестно найденных в литературе, это могут быть факты, цитаты, определения и т. д. Однако, всё, что написано в учебной литературе, давно является достоянием Интернета – плагиатом. Библиотеки из источника знаний превратились в источник плагиата. В этой связи, согласно рекомендациям Высшей школы, все использованные текстовые материалы должны перефразироваться, излагаться «другими», академическими словами. К сожалению, высшая школа молчит о критериях такого перефразирования. Данное молчание подтверждает ретроспектива статей, опубликованных на elibrary.ru, за последнее десятилетие, согласно контексту публикаций, отечественный научный мир, на исходе двух десятилетий существования антиплагиата, пытается понять, нужен антиплагиат высшей школе или нет.
Заметное разнообразие в «рефлексию» elibrary.ru вносят работы Н. В. Авдеева, В. В. Домакова [1], Т. А. Иващенко [3], В. П. Лукьяненко [4], Н. И. Мартишиной, В. В. Николаева [12], Н. Н. Пунчик, В. Г. Свечкарёва [3], В. И. Сперанского, Е. С. Стегниенко, В. В. Тимофеева и др.
Не смотря на попытки научного осмысления «антиплагиат-реальности», сегодня имеется несколько миллионов студентов, которые решают проблемы повышения оригинальности текстов, обращаясь к сервисам антиплагиат десятки миллионов раз за год. Растущий спрос на уникальные тексты породил сферу услуг – рерайт и перефразирование академических, научных текстов. Спустя почти два десятилетия феномена антиплагиата в России спрос на услуги академического рерайта не снижаются, а нарастают, несмотря на появление ИИ, который грозился оставить рерайтеров без работы. В этой связи назрела необходимость научного переосмысления реального положения вещей, обобщения, накопленных в сфере академического рерайта, практических наработок, способствующих успешному прохождению проверки в антиплагиат, версии ВУЗ.
Настоящая монография, посвящена одному вопросу – «как сделать рерайт, перефразирование в короткие сроки и успешно пройти проверку в антиплагиат. ВУЗ», основана на практическом опыте авторов и предназначена всем, кто стремится повысить уникальность текстов с наименьшими затратами и в сжатые сроки. В монографии не рассматриваются суррогатные методы обхода антиплагиата, предпочтение отдается рекомендуемому ВУЗами методу перефразирования, однако он представлен в совершенно ином аспекте, с позиции нового процесса, который мы называем КонтрПлагиат.
Работа представлена в авторской лексике и пунктуации, редактура осуществлена с применением инструкций в среде GPT, что демонстрирует современный уровень развитие ИИ решений.
1. Соотношение понятий КонтрПлагиата и антиплагиата
1.1. Процесс КонтрПлагиата для антиплагиата
Идея проверки текстов на плагиат не нова. Её прообразом выступают решения, применяемые в поисковых системах. Благодаря этому, нельзя выйти в топ поиска скопировав материалы с другого сайта. Копии таких текстов будут расцениваться поисковыми системами как плагиат, и, если он систематичен, сайт может попасть в серый или черный список, рис. 1.

Рисунок 1 – Как поисковые системы видят тексты
В погоне за уникальностью авторы контента прибегают к таким известным методам как рерайт (латентный, сокрытый плагиат – текст переписывается своими словами с сохранением смысловой нагрузки), или копирайтинг (написание нового, похожего текста). Это не всегда помогает, так как технологии развиваются и некоторые алгоритмы анализируют смысл текста, а не просто последовательность n-грамм (последовательность из n элементов, слогов, слов).
На уровне сервиса, предназначенного для проверки академических текстов на наличие заимствований, одним из первых, в 1997 г., появился Turnitin (сегодня – более 30 млн студентов, 15 000 организаций и учреждений). Turnitin – это интернет-сервис для проверки уникальности текстов, который управляется одноименной американской компанией, дочерним подразделением Advance Publications. Организация продает лицензии университетам и образовательным организациям, отличным от высшей школы. Эти субъекты образовательного процесса используют специализированный веб-сайт Turnitin в качестве портала (окна входа) услуги SaaS, что дает возможность сравнения представленных документов с содержимым базы данных Turnitin, таким образом, выявляются заимствования – плагиат.
Turnitin использует специализированные «секретные» алгоритмы для сравнения представленных работ с множеством текстов баз данных, чтобы проверить возможное наличие неоригинального контента.
В начале 2023 года Turnitin запустил новую функцию, направленную на обнаружение контента, созданного приложениями искусственного интеллекта, такими как ChatGPT. Однако, точность обнаружения контента, созданного искусственным интеллектом, остается предметом спора, в том числе и потому, что OpenAI, разработчик GPT, официально признал, что не умеет выявлять генеративные тексты.
Turnitin – сервис, который активно критикуется, это роднит его с отечественным антиплагиатом, который РУ и ВУЗ одновременно. С учетом опыта иностранной демократии некоторые зарубежные студенты отказываются от отправки работ на проверку, утверждая, что требование проверки подразумевает наличие вины, а действие презумпции невиновности никто не отменял. В отечественном, российском праве, по мнению О. В. Бобкова и С. А. Давыдова, плагиат является самостоятельным гражданским правонарушением, хотя нормы гражданского права не содержат в себе его состава в том виде, в котором в уголовном законе закреплен состав плагиата как преступления. «Наше право» предусматривает презумпцию невиновности в уголовном праве и презумпцию виновности в гражданском – это предположение, которое считается истинным до тех пор, пока ложность такого предположения не будет бесспорно доказана. Применительно к нашей теме, доказательством наличия или отсутствия плагиата выступает отчет сервиса по проверке работ на плагиат, который считается «первой, новационной, экспертной» системой, способной выносить заключение.
Некоторые зарубежные критики утверждают, что использование антиплагиат сервисов нарушает образовательную конфиденциальность и международное законодательство об интеллектуальной собственности, а также сохраняет работы авторов в частной базе данных антиплагиат сервиса для коммерческих целей.
Несмотря на все спорные вопросы, системы поиска плагиата процветают, выполняя десятки миллионов проверок. В марте 2019 года, Advance Publications приобрела Turnitin за 1,75 миллиарда долларов. В 2021 году, Turnitin приобрела конкурирующую компанию-разработчика программного обеспечения Ouriginal, которая сама по себе является результатом слияния Urkund и PlagScan.
Как подчеркивает Т. В. Хованская, система «Антиплагиат» имеет много общего с обычной поисковой системой. Однако, её «уникальность» заключается в том, что она способна анализировать не отдельные фразы, а целый документ. Размер этого документа может варьироваться от нескольких абзацев до тысяч страниц и быть практически любого текстового формата. В результате обработки запроса, система выдает детальный отчет, где заимствованные фрагменты отмечаются тегами. Кроме того, в правой части отчета появляется панель со списком источников и расчетом «процента оригинальности». Эта панель с перечнем источников является интерактивным инструментом, облегчающим подробный анализ заимствованного контента после машинного анализа, рис. 2. Система «Антиплагиат» также предоставляет возможность вносить изменения в полный отчет и пересчитывать результаты. К основным функциям редактирования отчета относятся отключение заимствованных источников, исключение отдельных заимствованных блоков и изменение типа источника с заимствованного на цитируемый и наоборот.
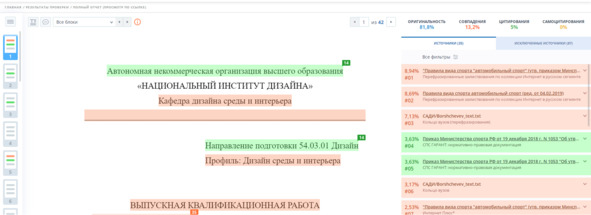
Рисунок 2 – Пример интерфейса с антиплагиат. ВУЗ-отчетом
Уточняя понимание Т. В. Хованской, отметим, что антиплагиат, в основе, является поисковой системой, поисковая система учитывает весь контекст, как целостность, отличие антиплагиата, в специализированной форме выдачи поискового результата.
В своей статье, И. Б. Стрелкова обращает внимание на то, что в 2005 году в Российской Федерации была создана специализированная поисковая система «Антиплагиат». Эта система была разработана с целью обнаружения текстовых заимствований и оценки их корректности. По мнению И. Б. Стрелковой, эту систему не следует рассматривать как «коммерческий продукт, навязанный научному и университетскому сообществу через искусственно созданный спрос». По ее мнению, антиплагиат, как явление, является необходимым элементом логики текущего этапа развития науки, на котором условия существования науки радикально трансформировались.
В контексте оценки системы «Антиплагиат», ее достоинств и недостатков, И. Б. Стрелкова приводит высказывание Н. И. Мартишиной: «Учитывая складывающуюся в стране ситуацию, использовать какую-либо систему проверки на плагиат (даже со всеми ее недостатками) – необходимо».
Ниже рассмотрим, как работает отечественная система антиплагиата, но не с точки зрения гуманитариев, а с точки зрения специалистов. Показатель уникальности текста представляет собой количественную меру, обычно выраженную в процентах. Как показывает практика, этот показатель вызывает интерес как у авторов, так и у их преподавателей. Данный показатель рассчитывается системами антиплагиата с помощью специально разработанных алгоритмов, которые держатся в строжайшем секрете и которые анализируют и исследуют текстовую комбинацию, отправленную на проверку. В простейшей интерпретации возможен следующий подход к толкованию процентов. Весь текст работы = 100%, если в работе 75 тыс. знаков, то 1% текста = 750 знакам. Если отчет о проверке показал 40% заимствований, то это означает, что работа содержит 40% * 750 зн. в 1% = 30 тыс. знаков текста плагиата.
Написание уникального текста, будь то реферат, курсовая или ВКР, может показаться на первый взгляд несложным процессом: грамотный подбор синонимов, перестановка слов и словосочетаний – и работа уникальна и готова к сдаче! Однако на практике оказывается, что реальность не так проста. Процесс проверки текста в системе антиплагиата проходит несколько этапов:
– Первичная обработка текста – удаление стоп-слов, знаков препинания и неалфавитных символов. Что может относится к стоп-словам: предлоги, а также слова не несущие смысловой нагрузки – без, быть, все, вы, для, его, есть, или, как, когда, кто, меня, мне, так, там, уже, чего, что, чтобы, этой, этом, этот, анализ, исследование, метод, результаты, данные, модель, проблема, теория, гипотеза, область, фактор, переменная, эффект, показатель, доказательство, вывод и т. д.
– Лемматизация – приведение слов к их нормальной форме, например, фраза: «Учитывая складывающуюся в стране ситуацию, использовать какую-либо систему проверки на плагиат (даже со всеми ее недостатками) – необходимо», примет вид «Учитывать складываться страна ситуация, использовать система проверка на плагиат (недостаток) – необходимо».
– Хеширование слов – каждое лемматизированное слово хешируется (предобразование в выходную битовую строку установленной длины) с помощью хеш-функции для унификации длины и упрощения сортировки.
– Формирование хеша шинглов (словосочетания из n-слов, n-граммы, рис. 3) – последовательность хешей слов представляется в виде значений, то есть перекрывающихся последовательностей из n хешей заданной длины шингла. Как правило, первично, используется шингл, состоящий из двух слов.
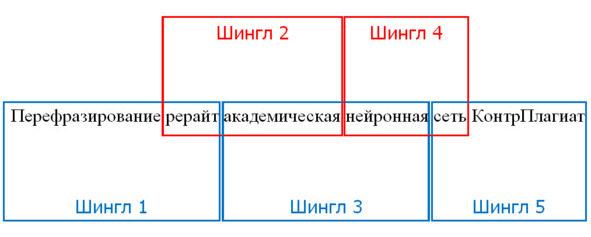
Рисунок 3 – Шинглы, состоящие из двух слов
– Хеширование значений шинглов.
– Запись хеша последовательностей с идентификатором текста и местоположением в тексте записывается в специальный файл, называемый индексом. Значения записываются в отсортированном порядке, что позволяет осуществлять двоичный поиск в индексном файле.
Из анализа алгоритма проверки уникальности текстов сервисом антиплагиат можно сделать следующие выводы:
– проверкой учитываются слова, несущие смысловую нагрузку. Введение в текст водянистых терминов – «по нашему мнению», «исходя из анализа», «подводя итог» и т. д. уникальности не прибавляет;
– изменение шинглов из двух слов (биграмм) приводит к повышению уникальности текстов, так как изменяется хеш шинглов;
– уникальность текста нужно повышать не фрагментарно, а целостно, так как это изменяет общее хеш-значение.
С учётом особенности процесса антиплагиат-проверки для создания качественного уникального научного текста используются три основных приёма:
– Обычный (легкий, поверхностный) рерайтинг. Для антиплагиат-сервисов, как правило, он не подходит, так как достигаемое отличие текстов (при сверке по шинглам из 2 слов – Ш2) не даёт возможности преодолеть порог срабатывания модуля перефразирования, преодоление которого возможно при показателе отличия текстов Ш2 = 80% и более процентов. Примером обычного рерайта является однократный перевод текста на иностранный язык и обратно на русский, при этом показатель Ш2 лежит в пределах 50—80%.
– Глубокий рерайтинг, текст «пересказывается» с использованием уникальных текстовых комбинаций, что существенно больше, чем перестановка предложений и замена синонимов. Глубокий рерайт даёт отличие текстов по методу сверки Ш2 на уровне 80 и более процентов. Пример глубокого рерайта – последовательный перевод на венгерский-русский + финский-русский + китайский-русский. При выборе языков желательно ориентироваться на объем искажений, получаемых в процессе перевода, наибольшее отличие рерайта от текста донора дадут лексически отдаленные языки, рис. 4, например финский.
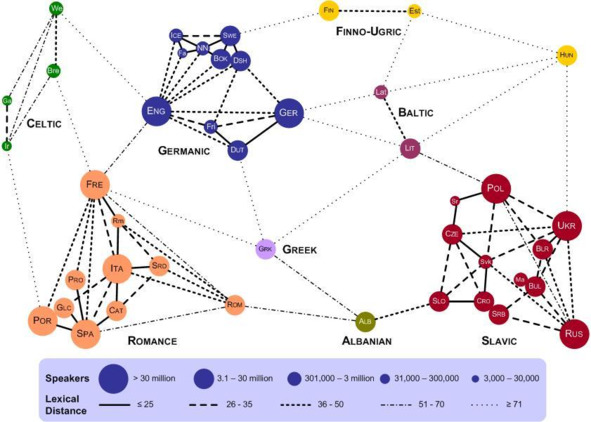
Рисунок 4 – Лексическое расстояние между европейскими языками
– Копирайтинг, оригинальный материал пишется «из головы», на основе глубокого понимания ранее полученного материала. Текст после копирайтинга отличается от источника при сверке по показателю Ш2 более чем на 80%, однако, нужно быть готовым к тому, что уникальность будет как у обычного или глубокого рерайтинга. Данная проблема, связанная с тем, что современные системы антиплагиат в погоне за «жесткостью» проверок давно уже грешат объективностью, а копирайтинг не предусматривает изменение n-грамм, которые относятся к терминам.
Рерайтерам и копирайтерам необходимо знать, что понятие уникальности материала по своей сути субъективно, его понимание зависит от множества внешних факторов. Каждый сервис антиплагиата по-своему понимает значение уникальности, поэтому во избежание кривотолков крайне важно исходить из потребности в проценте уникальности и учитывать, где проверяется текст:
Чтобы пройти проверку в StrikePlagiarism, достаточно получить отличия – Ш5 – 90—95%, Ш25 – 1—2%. Такое отличие дает перевод текста: венгерский-русский + китайский-русский.
Успешно пройти проверку в антиплагиат ВУЗ, потребует достижения показателя Ш2 – 90 и более процентов, рис. 5. Такое отличие возможно получить с помощью длинного цепочного перевода, но дефекты текста потребуют существенных трудозатрат на его редактирование.
РуКонтекст – отличие при сверке по показателю Ш2 – ваш показатель, который вы получите при проверке.
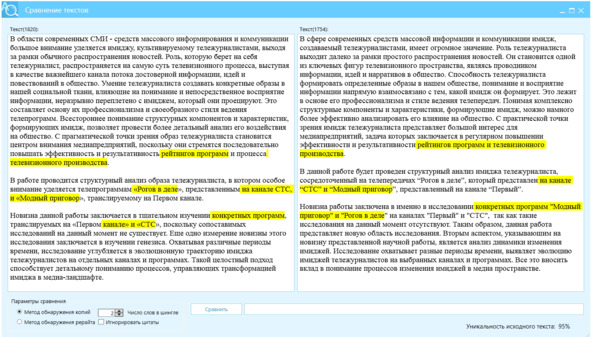
Рисунок 5 – Сверка текстов на отличие по показателю Ш2, левое окно – текст рерайта, правое окно – текст источник (донор), желтым выделены n-граммы, которые не изменились, показатель отличия см. внизу, справа = 95%
Что такое КонтрПлагиат? Как показано выше, рерайт (в частности, простой и глубокий) и копирайтинг не дают однозначного результата при проверке в антиплагиат, который РУ и ВУЗ. КонтрПлагиат свободен от этих недостатков, так как, применяя систему методов, он позволяет повышать уникальность с высоким отличием и позволяет проводить проверку текстов локально, на компьютере, бесплатно, за считанные секунды. Если показатель Ш2 больше 95%, то текст с высокой вероятностью пройдет любую проверку на антиплагиат в любой системе.
Разбивка шинглов (биграмм) в КонтрПлагиате – самостоятельный метод, его задача не оставлять в тексте желтых блоков, рис. 5, например вместо «Конституция Российской Федерации» – «Основной Закон нашей страны».
Диапазоны значений изменения текстов по показателю Ш2 могут варьироваться в достаточно большом диапазоне, что связано с объемом изменяемого текста. Если предложение содержит набор терминов, которые считаются неизменяемыми, то процесс перефразирования затрудняется и показатель Ш2 низок, например дан текст донор: «Государственную власть в РФ осуществляют Президент РФ, ФС (СФ и ГД), Правительство РФ, суды РФ. Государственную власть в субъектах РФ осуществляют образуемые ими органы государственной власти».
Имея текст с дефицитом изменяемой части, мы отходим от принципов рерайта и занимаемся чем-то иным, разбивая шинглы из 2 слов и придумывая слова и выражения, которые в обычной языковой практике, тем более научной не используются. Данный процесс называется КонтрПлагиатом. КонтрПлагиат может выглядеть следующим образом: «Функции органов, относимых к государственным, реализуют – высшее должностное лицо нашей страны – Президент, Собрание, на уровне Федерации, Совет, уровня Федерации и коллегиальный орган – Дума, государственного уровня, высший исполнительный орган Российской Федерации – Правительство, органы судебной власти РФ. Власть, уровня государства в субъектах, территориях нашей страны, реализуют образуемые специализированные органы, относимые к власти государства».
Ваш текст с правильно расставленными запятыми выглядит следующим образом:
Таким образом, для цели настоящей работы, предлагаются следующие константы:
– рерайт, способ изменения текста донора методом перефразирования «другими словами» для цели достижения уникальности;
– шингл, n-грамма – последовательность слов, биграмма – 2 слова (шингл из 2 слов, Ш2), триграмма – 3 слова (шингл из 3 слов, Ш3);
– легкий, поверхностный рерайт – перефразирование текста с уникальностью до 80%, при сверке по шинглам, состоящим из 2 слов;
– глубокий рерайт – перефразирование текста с уникальностью более 90%, при сверке по шинглам, состоящим из 2 слов;
– КонтрПлагиат – система методов, применяемых для перефразирования текста с уникальностью более 95%, при сверке по шинглам, состоящим из 2 слов;
– мягкая антиплагиат проверка – процент, полученный при локальной сверке биграмм (шинглов из 2 слов), = проценту уникальности антиплагиат проверки (например, РуКонтекст, антиплагиат ру – бесплатная версия);
– жесткая антиплагиат проверка, при нормальной заспамленности, процент, полученный при локальной сверке биграмм (шинглов из 2 слов), = проценту уникальности антиплагиат проверки (например, антиплагиат. ВУЗ) – минус 10%. Приведем пример: локальная проверка отличия текстов показала отличие по показателю Ш2 = 97%, ожидаемый результат оригинальности в отчете антиплагиат ВУЗ 87%, рис. 6;
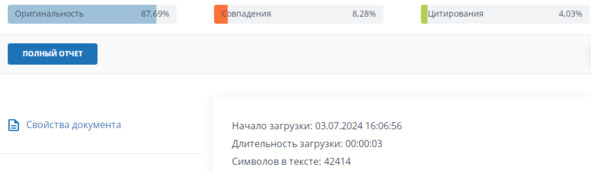
Рисунок 6 – Пример отчета в Антиплагиат, версии ВУЗ
– заспамленность, частотность текста – численная мера, показывающая популярность текста, например, в педагогических работах, посвященных младшему школьному возрасту, теоретическая часть содержит возрастную характеристику детей данного возраста, сколько работ о младшем школьном возрасте написано за последние 20 лет?

